Процессор изнутри. Часть 3: AMD — Архив WASM.RU
Процессор изнутри Процессор изнутри. Часть 3: AMD
В данной части мануала наконец-то дошла очередь и до AMD. Описание ведется по стандартной схеме – интерфейс, кэш, ядро, мониторинг производительности.
Данная статья относится именно к Athlon и частично к Athlon XP. Частично, потому что блок-схемы практически совпадают, но у XP больше событий, чем в «просто Athlon». Дополнительные события будут рассмотрены в следующей части.
Интерфейс процессора.
Процессоры AMD используют шину EV6 для интерфейса с чипсетом. Сигналы этой шины приведены ниже. К сожалению, процессоры Athlon и Duron не предоставляют средства мониторинга событий на шине, поэтому посмотреть на все с практической стороны не получится.
CFWDRST
Сброс синхронизации.
CONNECT
Используется для управления энергопотреблением и начальной инициализацией процессора.
PROCRDY
Используется для управления энергопотреблением и начальной инициализацией процессора.
AIN[14:2]#
Шина входящих адресов.
AINCLK#
Синхронизация шины входящих адресов.
AOUT[14:2]#
Шина исходящих адресов.
AOUTCLK#
Синхронизация шины исходящих адресов.
D[63:3]#
Шина данных.
DICLK[3:0]#
Синхронизация входящих данных.
DOCLK[3:0]#
Синхронизация исходящих данных.
DINVAL#
Сигнал «Data Invalid» вводится чипсетом для введения задержки между шинными циклами обмена данными.
CPURST
Сброс процессора.
INTR
Маскируемое прерывание.
NMI
Немаскируемое прерывание.
INIT
Мягкая инициализация процессора.
STPCLK#
Сигнал используется для управления частотой синхронизации (управление синхронизацией используется для снижения энергопотребления)
SMI#
Вход в режим SMM.
FERR#
Ошибка сопроцессора.
IGNNE#
Игнорировать ошибки сопроцессора, сигнал нужен для совместимости с 286.
SLP#
Перевод процессора в спящий режим.
A20M#
Маскирование старших разрядов адреса. Нужен для совместимости.
FID[3:0]
По этим линиям процессор сообщает системе какой коэффициент умножения использует ядро.
PICCLK
Синхронизация шины APIC
PICD[1:0]#
Шина данных APIC
PWROK
Сигнал процессору со стороны системы, что питание в норме.
SYSCLK
SYSCLK#
Этот и предыдущий сигналы – дифференциальные входы общей синхронизации процессора.
В общем-то, особо обсуждать нечего, все достаточно просто. Процессор и система обмениваются адресами и данными, используя отдельные линии синхронизации для входящего и исходящего потока.
Синхронизация от источника позволяет достичь высокой пропускной способности – до 1,6 Гб/c.
Ряд сигналов заимствован из шины GTL+, в частности все сигналы, предназначенные для совместимости процессоров – IGNNE#, FERR#, A20M# и т.д.
Кэширование.
В процессорах AMD применяется двухуровневая иерархия кэша.
В качестве алгоритма замещения строк используется LRU.
Иерархия TLB также включает 2 уровня – и разделена на TLB кода и данных. То есть в процессоре Athlon 4 буфера TLB.
24-входовый ITLB-L1.
32-входовый DTLB-L1.
256-входовые L2 ITLB и DTLB.
Для каждой модели процессора размеры TLB можно узнать по инструкции CPUID.
TLB делятся также для больших и малых страниц, причем делятся довольно интересным образом – в L1-ITLB например, 16 строк используются для кэширования адресов малых страниц в 4Кб, а оставшиеся 8 – для больших страниц. Похожим образом организован и L1-DTLB.
TLB второго уровня могут работать только с малыми страницами.
Протокол когерентности.
В процессорах AMD реализован более продвинутый протокол когерентности кэша – MOESI. M, E, S и I нам уже знакомы. O-состояние строки устанавливается в случае записи в S-строку и указывает что кэшируемый адрес присутствует в кэше не только этого процессора и данные модифицированы. Любые попытки чтения по данному адресу должны обслуживаться только из этой строки кэша.
То есть если процессор обнаруживает попытку чтения по данному адресу, он должен передать запрашивающему процессору данные из своего кэша.
Запись в O-строку может выполняться процессором многократно. O-состояние сохраняется до того момента, пока какой-то из процессоров (кроме того, который содержит данную строку) не выполнит запись по данному адресу, это приведет к выгрузке O-строки в память, поскольку хозяин (owner) у данных может быть только один.
Теоретически, S и O строки могут появляться в кэше, только если в системе присутствует несколько процессоров.
На практике дело выглядит так (Вы можете проверить это самостоятельно, используя Processor spy):
S-строки появляются в кэше, причем, довольно активно, O-строк не появляется ни при каких условиях.
Разберемся, почему так происходит. S-строка появляется в кэше в результате обращения к данным со стороны DMA. Так как ОС использует буферизацию ввода вывода, то это неудивительно. O-строки не появляются в кэше потому, что процессор «видит» с помощью специальных контактов в сокете что он в системе один, так как процессор не может передать данные из своего кэша винчестеру, он не создает O-строк, запись в S-строку в данном случае приводит к выгрузке строки в память.
Ядро.
Ядро процессоров с архитектурой AMD использует другие принципы своего функционирования, по сравнению с intel. По сути Athlon является RISC процессором – в режиме реального времени выполняется преобразование потока CISC команд в унифицированные RISC команды, которые согласно AMD-шной терминологии называются MacroOps.
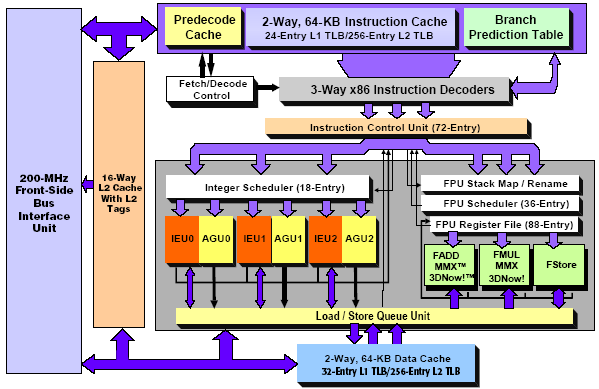
Блок-схема процессора приведена ниже.
Выборка, декодирование.
Когда инструкции попадают в L1 (после заполнения строки) начинается преддекодирование (predecode) которое определяет длину инструкции и некоторую другую информацию, все это сохраняется в специально отведенных для этого местах в самом кэше инструкций (эти места называются predecode cache). Формат строки кэша не раскрывается, и о расположении информации преддекодирования можно только догадываться. Когда в потоке преддекодирования встречается переход, он прогнозируется, и процесс преддекодирования продолжается с предсказанного адреса.
Механизм прогнозирования более продвинутый, чем у Intel-овских аналогов, в частности используется не только таблица BTB, но и таблица глобальной истории переходов GHBC (Global History Bimodal Counters). Подробнее о таблице GHBC см. следующую часть мануала про Opteron и Athlon-64 – для этих процессоров AMD раскрыла некоторые параметры GHBC вроде размера, там проще разбираться.
Пока скажу только что если BTB позволяет предсказывать переходы исходя из информации о предыдущих исходах именно этой команды, то GHBC позволяет учесть при прогнозировании и исходы определенного количества условных переходов выполненных до текущего.
Еще применяется прогнозирование адреса возврата, используется специальный буфер в который заносится следующий EIP после выборки CALL. При выборке ret процессор достает адрес возврата из своего буфера, а не из стека (попытки его перезаписать отслеживаются).
После того как определен тип операции, команда направляется в один из 2-х декодеров называемых DirectPath и VectorPath. Они преобразуют команды х86 в унифицированные макрооперации (MacroOPs) с фиксированной структурой, и использующими больший набор регистров (преобразование CISC-to-RISC).
VectorPath применяется для сложных команд которые не могут быть преобразованы в одну макрооперацию.
Схема декодирования выглядит следующим образом:
MROM – Microcode ROM которая, как говорилось выше, применяется для декодирования сложных команд.
В результате преддекодирования процессор принимает решение относительно того, куда направить данную команду на декодирование – в DirectPath или в VectorPath.
DirectPath выполняет прямое (direct) декодирование одной команды в одну макрооперацию.
VectorPath декодирует сложные команды. Код операции является «точкой входа» в таблицу микрокода, судя по рисунку, используется адресация макроопераций с ветвлением. Суть этого подхода в том, что адрес следующей макрооперации хранится в полях самих макроопераций. Достаточно указать только точку входа, далее выбрать макрооперацию с соответствующим индексом, извлечь из нее адрес следующей и т.д. до тех пор, пока не будет извлечена макрооперация с установленным флагом “END” (так он условно называется в литературе). После этого микропрограмма для команды полностью сформирована, и можно приступать к декодированию следующей команды.
Похожий подход (только с другими названиями) используют и процессоры intel. Это вообще стандартный метод для реализации нескольких способов адресации. В процессе декодирования процессор анализирует текущий способ адресации (прямая, косвенная, косвенная со смещением и т.д.) и на основании этой информации строит микропрограмму. Макрооперации в микропрограмме друг с другом никак не связаны, с том смысле, что могут выполняться и неупорядоченно. Правильная последовательность обеспечивается только тем, что они зависят друг от друга по данным.
Диспетчеризация.
Далее, макрооперации поступают в ICU, (Instruction Control Unit) который является «нервным центром» всего процессора, здесь выполняется диспетчеризация и управление потоком команд, переименование регистров.
Буфер переупорядочивания имеет 24 строки, в каждой размещается 3 макрооперации.
После выполнения всех операций переименования регистров и переупорядочивания микрооперации направляются в планировщики, каждое исполнительное устройство использует свой планировщик.
Планировщик разбивает макрооперации на микрооперации, которые могут быть выполнены исполнительными устройствами.
Микроопераций 2 вида – вычисления адреса и операционные.
Преобразованные микрооперации хранятся в самом планировщике, который имеет буфер (резервационную станцию) на 18 вхождений.
Далее, микрооперации в соответствии с готовностью направляются в исполнительные устройства.
Исполнение.
Целочисленное устройство выглядит так:
Одна из причин, по которым Athlon очень часто «делает» интеловские аналоги в тестах FPU заключается в том, что он имеет крайне продвинутый блок операций с плавающей точкой.
Это больше чем просто блок для FPU операций, по сути, это отдельный процессор. Используется отдельный блок переименования регистров, собственный планировщик и собственные исполнительные устройства.
У intel хотя и используются разные функциональные блоки, регистры FPU имеют такой же статус, как и регистры IEU и обслуживаются одной и той же RAT и ROB.
Здесь же имеем полную изоляцию от целочисленного устройства.
После выполнения микроопераций в работу включается LSU (Load/Store Unit). Шины результата заведены именно на него. Кроме того, строки буфера могут использоваться как операнды.
Результат микрооперации хранится в LSU до тех пор, пока не будет выполнено восстановление команды. Затем, после восстановления команды, значение из LSU переписывается либо в постоянные регистры, либо в кэш данных.
Восстановление.
Восстановление включает в себя все те же операции – запись результата в постоянные регистры, удаление записей о микрооперациях и макрооперациях из всех буферов и инкремент EIP на длину команды.
Мониторинг производительности.
Формат управляющих регистров счетчиков такой же, как у intel P6, зато счетчиков уже не 2, а 4. Кроме того, бит Enabled не разделяется всеми счетчиками как у intel, то есть счетчик может работать либо не работать независимо от других счетчиков.
Управляющие регистры имеют адреса C0010000h-C0010003h. Сразу же за ними, по адресам C0010004h-C0010007h расположены и сами счетчики. События мониторинга также отличаются, они приведены на следующей таблице. В AMD счетчики имеют разрядность 48 бит против 40 бит у intel.
Назначение полей регистра рассматривалось в Intel P6.
Нельзя не отметить очень удобное расположение регистров, например, в intel P6 остановить и обнулить счетчики можно так:
Код (Text):
MSR_SERVICE.WriteToMSR(index,data) выполняет запись значения data в MSR регистр с индексом index.
Для AMD процесс происходит так:
Код (Text):
Если бы сначала располагались счетчики, а потом – их управляющие регистры, то такой код не работал бы. Сначала нужно записать 0 в управляющий регистр, а только потом в сам счетчик, в противном случае счетчик никогда не будет обнулен. При записи нуля в счетчик он будет продолжать считать с нуля, до того времени пока не остановится записью в управляющий регистр.
Processor spy.
По сравнению с интеловскими собратьями, список событий несколько бедноват, но, спасибо и за то, что есть.
Необходимо учесть тот факт, что процессор имеет счетчиков больше чем P6, при этом они независимы друг от друга, и используется, в отличие от Pentium 4, удобный механизм программирования – золотая середина, еще бы событий побольше, было бы вообще замечательно.
Таблица событий прилагается вместе с исходниками очередного Processor spy.
Файлы: athlon.zip, procspy_amd.zip
© Dark_Master
Процессор изнутри. Часть 3: AMD
Дата публикации 15 фев 2005