Процессор изнутри. Часть 2: INTEL NetBurst — Архив WASM.RU
Интерфейс процессора.
Шина Pentium 4 называется AGTL+ и использует практически тот же набор сигналов, что и обычная GTL+ применяемая в процессорах P6. Вместе с тем, используется принципиально новый механизм синхронизации позволяющий добиться частоты передачи данных гораздо больше чем в P6.
Ниже приводится таблица сигналов процессора.
Сигнал
Описание
A[35:3]# - Address
36-битный физический адрес, т.к. шина данных 64-битная младшие 3 бита адреса всегда равны нулю (обмен с памятью всегда идет пакетами по 8 байт).
A20M# - 20th address line mask
Маскирование старших разрядов адреса для эмуляции 8086, данный сигнал подается на процессор при установке Gate A20 в «закрытое состояние».
ADS# - Address strobe
Строб адреса, переход этого сигнала в активное состояние указывает на начало новой транзакции, вводится инициатором обмена.
ADSTB[1:0]# - Address strobes
Стробы линий A[16:3], REQ[4:0] и A[35:17], по спаду передается адрес, по фронту – информация о типе транзакции.
AERR# - Address parity error
Ошибка паритета на шине адреса.
AP[1:0]# - Address parity
Биты паритета адреса.
BCLK[1:0] – Bus clock
Общая синхронизация шины.
BINIT# - Bus initialization
Инициализация шины, перевод всех сигналов в начальное состояние.
BNR# - Block next request
Запрос приостановки следующей транзакции. Вводится любым устройством когда оно не может воспринять следующую транзакцию. С помощью счетчиков можно посчитать такты в течение которых этот сигнал установлен.
BPM[5:0]# - Break point / Performance monitoring
Сигналы применяемые при попадании в точку останова или срабатывание счетчиков мониторинга производительности.
BPRI# - Bus request priority
Используется для арбитража запросов к шине со стороны нескольких процессоров в мультипроцессорной системе.
BR0# - Bus request
Запрос на владение шиной.
D[63:0]# - Data bus
Шина данных.
DBI[3:0]# - Data bus inversion
Инверсия данных на линиях D[63:0]. Шина данных разделяется на 4 участка по 16 линий в каждом, данные на каждом участке могут передаваться как в прямом так и в инвертированном состоянии, цель этого метода – чтобы одновременно на шине было как можно больше сигналов в одинаковом состоянии. Это позволяет уменьшить помехи и частые переключения линий из одного состояния в другое и повысить частоту шины. Это свойство присуще только Pentium 4.
DBSY# - Data bus busy
Шина данных занята, используется текущим владельцем шины чтобы указать остальным процессорам на занятость шины.
DEFER# - Deferred
Сигнал указывающий процессору что исходный порядок транзакций не гарантируется. В ряде чипсетов сигнал не используется.
DP[3:0]# - Data parity
Паритет шины данных.
DSTBn[3:0]# , DSTBp[3:0]# - Data strobes
Дифференциальные стробы шины данных.
DRDY# - Data ready
Устанавливается источником данных для указания на достоверность данных на шине.
FERR# - FPU error
Ошибка FPU
FLUSH# - Cache flush
Сигнал заставляющий процессор выполнить выгрузку содержимого кэшей обоих уровней в память и перевести все строки в состояние Invalid.
HIT# - Cache hit
Указывает на кэш-попадание для текущего адреса, формируется как результат цикла слежения (см. раздел «Кэширование»).
HITM# - Cache hit “Modified”
Указывает на попадание в модифицированную строку. Другим процессорам запрещается обращаться к этим данным в памяти до выполнения обратной записи.
IERR# - Internal error
Обнаружена внутренняя ошибка.
IGNNE# - Ignore numeric errors
Игнорировать ошибки сопроцессора, исключения не вырабатываются.
INIT# - Initialization
Сигнал «мягкой» инициализации процессора (не производится BIST, процессор просто переключается в реальный режим и переходит к адресу начального вектора).
LINT[1:0] – Local Interrupt
Шина APIC, если APIC запрещен – сигналы превращаются в стандартные INTR и NMI.
LOCK#
Блокировка шины на время транзакции, сигнал устанавливается на время выполнения команды вызывающей транзакцию с префиксом LOCK.
MCERR# - Machine check error
Неисправимая ошибка в результате аппаратного сбоя.
PROCHOT#
Перегрев процессора (используется в процессорах со встроенным термоконтролем).
REQ[4:0]# - request
Линии по которым абоненты шины определяют тип активной транзакции (memory reference, I/O, write-back, burst R/W и т.д.), вводится владельцем шины.
RESET#
Без комментариев : -)
RS[2:0]# - Response status
Состояние ответчика, линия управляется устройством ответственным за завершение транзакции.
RSP# - Response status parity
Паритет для линий RS[2:0]#
SMI# - System management mode
Вход в режим SMM
TRDY# - Target unit ready
Сигнал, указывающий на готовность целевого устройства.
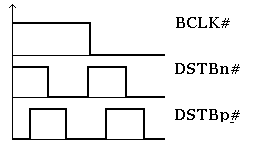
Самая неожиданная вещь, что по этой шине данные могут передаваться с частотой 400МГц и более, при том, что частота синхронизации шины всего 100МГ, как и в P6. Этот эффект достигается следующим образом:
стробы данных DSTBn# DSTBp# изменяются с частотой 200МГц и сдвинуты друг относительно друга на половину своего маленького периода. Синхронизация шины данных осуществляется по спаду этих стробов. То есть получается, что за один такт шины синхронизируемой по BCLK# на линиях DSTBn# и DSTBp# успевает появиться 4 фронта и 4 спада.
Таким образом, достигается частота передачи данных больше 100МГц. Теоретически, можно довести частоту и до 800МГц – если использовать подход аналогичный DDR, то есть использовать синхронизацию не только по спаду, но и по фронту.
Кэширование.
Кэширование в процессорах с архитектурой NetBurst имеет 3 уровня. Кэш L3 есть правда не у всех процессоров, а только у самых экстремальных – Intel Xeon и Intel Pentium 4 Extreme Edition.
«Стандартный» Pentium 4 имеет кэш L2 объемом 256Кб расположенный полностью на кристалле и работающий на частоте ядра. Длина строки кэша 64 байта, такая строка не может быть заполнена за один пакетный цикл и поэтому применяется секторирование кэша (см. ниже). Для обеспечения мультипроцессорной когерентности применяется все тот же алгоритм MESI.
Кэш L1 для данных имеет размер 64Кб и длину строки 64 байта, как и L2.
Кэша L1 инструкций больше нет. Вместо него используется 8-ассоциативный Trace cache, о принципах работы которого рассказывается ниже. Его размер не сообщается – говорится лишь, что он может хранить 12К микроопераций, при этом размер и формат самих микроопераций неизвестен.
Секторирование кэша.
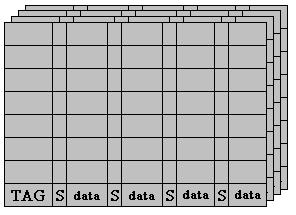
В процессорах Pentium 4 появился так называемый sectored-cache – секторированный кэш. Он отличается от обычного тем, что имеет большую длину строки, для того чтобы заполнить эту строку недостаточно одного пакетного цикла. Увеличивать глубину индекса строки – значит продлевать циклы заполнения строк данными, которые могут и не понадобиться. Поступают по-другому - строка делится на секторы, размер которых выбирается таким, чтобы заполнение происходило за один пакетный цикл. Затем, для каждого сектора выделяются свои собственные биты достоверности. Заполняются секторы независимо друг от друга.
Важно понимать разницу между набором и сектором – набор – некоторое количество строк кэша, отличающихся старшими частями адреса, сектор – то из чего состоит строка, все секторы имеют один и тот же старший адрес – поле TAG той строки, в которую входит данный сектор.
Физический адрес в таком случае делится уже на 4 части: TAG, Index, Sector, Offset.
Когда процессор выбрал набор через index и нашел совпадение тега, он через поле sector определяет сектор в строке и проверяет состояние сектора, после чего, если данные достоверны выбирает нужный байт из сектора используя поле offset.
Если изобразить секторированный, 4-ассоциативный, 4-секторный кэш по тому же принципу что ранее обычный то получиться что-то вроде этого:
Как уже говорилось, за один пакетный цикл происходит заполнение только одного какого-то сектора, а не всей строки.
Ядро.
В процессорах Pentium 4 архитектура ядра перешла на новый виток развития архитектуры IA-32. Pentium III скорее маркетинговый шаг, а не новая концепция в процессоростроении. Дело в том, что нужно было чем-то ответить на AMD K6-III, а ничего подходящего под рукой не было. Поэтому на скорую руку слепили SSE и пристроили его в Pentium II.
На мой взгляд, Pentuim III могут называться только процессоры начиная с ядра Coppermine. Katmai, под Slot 1 по-моему «не тянет» на Pentium III, несмотря на то, что носит это имя на корпусе.
Но я отвлекся, займемся Pentium 4.
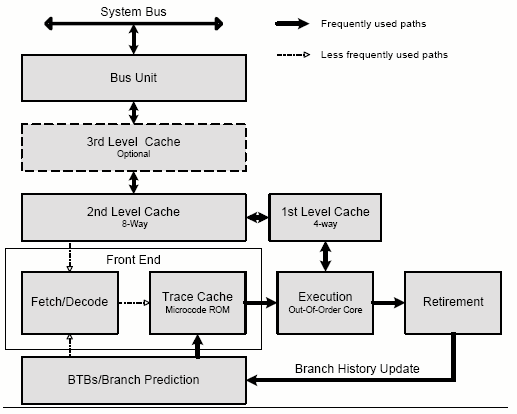
Посмотрим на блок-схему процессора. Кэш L3 есть только в процессорах Xeon и в Pentium 4 Extreme Edition, и на него пока можно внимания не обращать. Данная схема упрощена, немного позже мы рассмотрим более подробный вариант.
Выборка, декодирование и построение трассы.
Процессор работает следующим образом: блок выборки пытается выбрать очередную команду из L2. В случае если ее там нет – производятся операции заполнения строки и в конечном итоге нужная строка оказывается в L2 и выбирается оттуда. Далее, строка декодируется в микрооперации и строится «трасса исполнения» из последовательности микроопераций. Эта последовательность заносится в Trace Cache с сохранением порядка микроопераций, то есть все переходы и т.д. учитываются при построении трассы. Trace Cache при этом находится в режиме построения (build). После того как трасса построена, кэш переходит в режим «поставки» (delivery) микроопераций.
Инструкции могут поставляться ядру и из недостроенной строки, важно только чтобы там была та микрооперация, которая нужна.
Кэширование не инструкций, а трасс и есть ключевой момент архитектуры. Если требуемые ядру инструкции есть в кэше, для них не требуется выполнять декодирование.
Обеспечение правильного порядка возлагается на декодер.
Таким образом, сделана попытка убрать ступень декодирования для тех команд, которые уже исполнялись.
Следует отметить, что Trace cache не хранит все микрооперации, которые нужны программе. Некоторые сложные команды, по-прежнему поступают на выполнение из памяти микрокода. Для этой цели служат MROM-векторы. Эти векторы помещаются в Trace Cache вместо длинных последовательностей микроопераций. Когда процессор извлекает такой вектор, он обращается к памяти микрокода (происходит событие Uop delivery changing from TC to MROM).
Кэш трасс тесно связан с блоком предсказания ветвления. Благодаря BTB, в кэш трасс не попадают микрооперации, которые никогда не будут исполняться.
Переименование регистров и предсказание перехода происходит до построения трассы.
Pentium 4 поддерживает программные «подсказки» на переходы, для этого введены 2 новых префикса – 3Eh если переход будет и 2Eh если нет. Префиксы ставятся перед командами условных переходов.
Буфер BTB в P4 хранит 4К данных, то есть адреса 1024 команд перехода. В качестве адреса команды используется ее линейный адрес.
В процессоре применено также очень интересное решение, которое называется RAS (Return Address Stack). Суть его сводится к тому, что процессор кэширует вершину стека в своих внутренних регистрах. При интенсивной работе со стеком, например в случае частых вызовов процедур, если все изменяемые данные помещаются во внутренний стек процессора – обращение к вершине стека будет занимать примерно такое же время, как и обращение к кэш-памяти первого уровня, что существенно быстрее обращения в основную память.
Для переименования регистров используется механизм похожий на P6 с RAT и ROB размеры и детали реализации которых не сообщаются.
Диспетчеризация и исполнение.
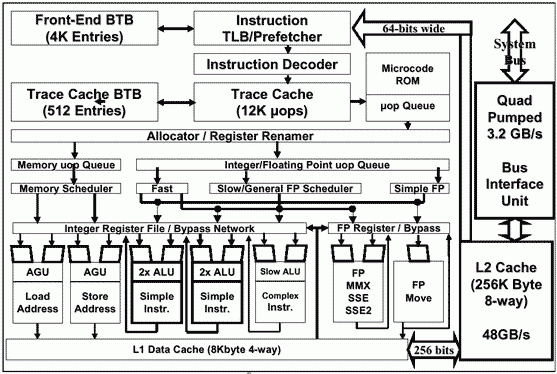
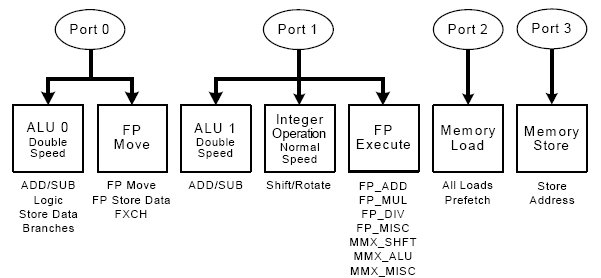
Посмотрим на подробную схему процессора:
Ядро использует те же принципы неупорядоченного спекулятивного исполнения, что и ядро P6. Процесс обработки четко разделяется на Front End выполняющий выборку, декодирование и построение трассы исполнения в порядке программы и Back End, который включает ядро, неупорядоченно выполняющее микрооперации, и подсистемы ответственные за неупорядоченное исполнение.
Исполнительная часть ядра имеет 4 порта доступа, они показаны на рисунке.
Микрооперации из Trace cache поступают в эти порты, после чего - в очереди выполнения и выполняются ядром.
Микрооперации могут поступать в порты еще до того, как выполнены все условия для их «штатного» выполнения, могут быть не готовы операнды микрооперации, либо она может находиться в неподтвержденной ветви перехода.
При этом предполагается, что к тому времени, когда дело дойдет до исполнения, все эти условия будут выполнены, в случае осечки (например, промаха кэша, где должен быть операнд) микрооперация должна быть переиздана (reissue). Согласно интеловской терминологии, переиздание микрооперации называется replay.
Восстановление (retirement).
Операция восстановления выполняет те же операции что и в P6 – извлечение результата операции и сохранение его в постоянных регистрах, инкремент EIP на длину команды и т.д.
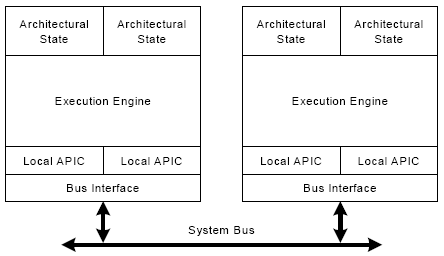
HyperThreading.
HyperThreading – технология впервые примененная intel в процессорах Pentium 4. Если она включена (через BIOS) и поддерживается ОС, то последняя видит 2 «логических» процессора, которые поддерживаются одним физическим.
Этот эффект «двухпроцессорности» достигается применением двух наборов регистров и двух локальных контроллеров прерываний APIC (и соответствующей их поддержке), при этом набор функциональных блоков остается тем же, логические процессоры не существуют отдельно друг от друга, а конкурируют за ресурсы единственного физического процессора.
Разные логические процессоры используют разные регистровые файлы, у каждого из них свой поток выполнения, но разница, по сравнению с двухпроцессорной системой, заключается в том, что микрооперации, декодированные из обеих ветвей исполнения, попадают в одни и те же порты исполнения и функциональным блокам приходится «работать за двоих».
На рисунке показана двухпроцессорная система на базе процессоров NetBurst с поддержкой HT.
Т.к. порты исполнительного устройства могут работать абсолютно параллельно, то при надлежащем планировании со стороны ОС (например, поток, интенсивно использующий FPU на одном логическом процессоре и поток, загружающий целочисленное устройство - на втором) может быть достигнут настоящий параллелизм в выполнении процессов до этого доступный лишь многопроцессорным системам. При плохом планировании (когда процессы, использующие одно и то же исполнительное устройство «вешаются» на разные процессоры) преимущества технологии незначительны.
Устройство восстановления различает команды разных процессоров и восстанавливает их в соответствующие регистровые файлы RRF.
Есть еще момент относительно определения поддержки процессором этой технологии. Бит 28 в EDX (поддержка HT) при выполнении CPUID(1) у всех процессоров NetBurst установлен в 1. ОС определяет поддержку этой технологии на том этапе, когда считает количество процессоров в системе. Если процессор поддерживает HT, ОС будет видеть 2 процессора.
Мониторинг производительности.
В процессорах Intel Pentium 4 (и других процессорах с архитектурой NetBurst, например Xeon) механизм мониторинга производительности в очередной раз претерпел коренные изменения. Способы программирования счетчиков организованы довольно замысловатым образом.
Сначала рассмотрим систему в общем, потом разберемся с деталями.
Видимо, устав выслушивать заявления что, дескать, как это так, что в AMD 4 счетчика, а в intel всего 2, последняя решила не мелочиться и в Pentium 4 существуют уже 18 счетчиков производительности, упомянутый процессор отличается также самым заумным механизмом программирования.
С каждым из счетчиков ассоциирован особый регистр CCCR (Counter Configuration Control Register) который не имеет аналогов в архитектуре P6, через него разрешается / запрещается счет, производится фильтрация событий и т.д., кроме того, через него выбирается блок управляющих регистров счетчика ESCR (Event Select Control Register), с каждым счетчиком (и CCCR) ассоциирован свой набор управляющих регистров, данный счетчик может считать только те события, на которые он может быть настроен посредством соответствующих ему управляющих регистров.
Таким образом, в общем случае счетчик не может считать любые события. Предпосылки этой системы были еще в P6, где в строке комментария события могло быть Counter 0 only или Counter 1 only, но если в Р6 обособление счетчиков – исключение, то в NetBurst – общее правило.
Согласно рекомендациям Intel программирование счетчиков должно происходить по следующему алгоритму:
1) Определить события для счета.
2) Определить набор регистров ESCR, поддерживающих данное событие.
3) Установить соответствие между CCCR регистром и группой ESCR.
4) Настроить ESCR на нужное событие.
5) Через поле в CCCR ESCR-select выбрать группу ESCR, в которую входит нужный регистр.
6) Задать дополнительные параметры в CCCR (фильтрация, маски, прерывания по переполнению).
7) Включить счетчик, ассоциированный с данным регистром CCCR.
Считывать естественно надо тот счетчик, с которым ассоциирован данный CCCR.
К мануалу прилагается таблица соответствий между регистрами, через нее можно узнать. какие ESCR с какими CCCR ассоциированы, и адреса всех регистров.
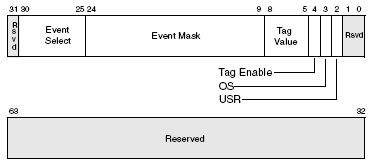
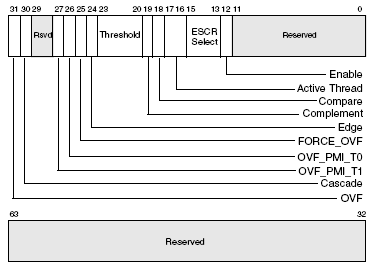
Формат ESCR следующий:
Тут все по аналогии с P6, новое только поле тега. Оно применяется для того, чтобы различать по какому-либо признаку однотипные операции, например типы микроопераций для события uOPs retired.
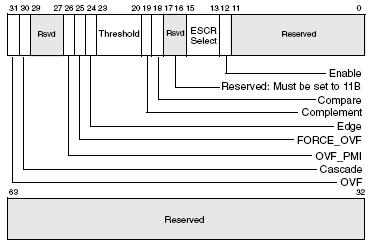
Формат CCCR:
Enable – включение счетчика ассоциированного с данным CCCR.
ESCR select – сюда заносится значение из 6-го столбца таблицы для выбора группы ESCR.
Compare – включает механизм фильтрации событий.
Complement и Threshold выполняют ту же функцию что и Counter mask в P6: если complement=0 то счетчик инкрементируется в случае если за такт произошло событий больше либо равно значению Threshold, если complement=1, то счетчик инкрементируется если событий меньше чем значение threshold.
Edge – то же самое что и Edge detect для P6.
FORCE_OVF – принудительное переполнение счетчика в результате каждого инкремента (и генерация прерывания по переполнению).
OVF_PMI – разрешение генерации прерываний по переполнению.
Cascade – включает счет на второй счетчик из пары, если один из счетчиков переполнен.
OVF – если установлен – счетчик был переполнен в процессе работы.
Зарезервированные области в CCCR связаны с HyperThreading (см. ниже).
Через них можно выбирать для какого из виртуальных процессоров вести счет.
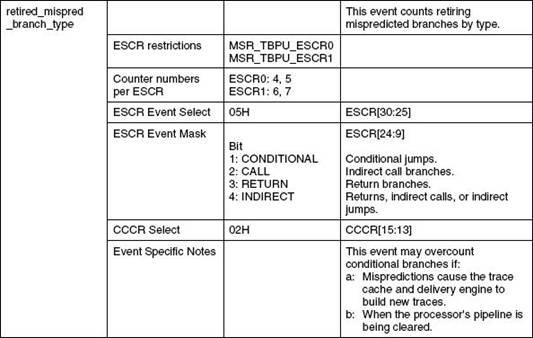
Для примера того, как описывается событие, приведу скриншот из мануала, описание события для Pentium 4 Retired mispredicted branches:
На первый взгляд даже не совсем понятно как ей пользоваться, на деле все довольно просто, но до этого нужно «дойти».
Строка ESCR restrictions показывает, какие ESCR поддерживают данное событие, в нашем случае это MSR_TBPU_ESCR0 и MSR_TBPU_ESCR1.
Вторая строка Counter number per ESCR показывает какие счетчики могут считать эти события, эта строка введена только для удобства, эти номера можно определить и из вышеприведенной таблицы соответствий, если в списке ассоциированных со счетчиком ESCR присутствуют регистры, указанные в ESCR restrictions значит счетчик пригоден для счета.
ESCR Event select указывает значение одноименного поля в ESCR.
ESCR Event mask указывает маску счетчика, в нашем случае там может комбинация из 4 битов.
ESCR select указывает значение одноименного поля в регистре CCCR ассоциированном со счетчиком. Это значение тоже приводится для удобства, его также как и Counter number per ESCR можно найти из таблицы соответствий напротив соответствующего ESCR-а
Теперь можно рассмотреть выбор этого события с практической стороны:
1) Определяем, что событие поддерживается только MSR_TBPU_ESCR0 или 1 извлекаем из таблицы соответствий их адреса – 3С2 и 3С3 соответственно.
2) Выбираем событие путем загрузки в регистры по приведенным адресами значений Event select и Event mask в соответствующие поля: 05h для события и, к примеру будем считать call-ы, 0010 в поле маски.
3) Загружаем значение режима мониторинга – OS mode, User mode или All modes.
4) Определяем регистр CCCR поддерживающий наши ESCR-ы – это MSR_MS_CCCR0,1,2,3 с адресами 364,365,366,367.
5) Загружаем в поле ESCR select одного из них (скажем MSR_MS_CCCR0) значение соответствующее MSR_TBPU_ESCR0 – 02h.
6) Устанавливаем фильтрацию и каскадирование по нашему усмотрению.
7) Включаем счетчик установкой бита E в CCCR.
8) Определяем счетчик, ассоциированный с нашим регистром CCCR – это MSR_MS_COUNTER0 с адресом 364. Он является 4-ым по порядку счетчиком.
9) Считывать счетчик можно командой RDPMC при ECX=4.
Еще нужно обратить внимание на терминологию. Non-retirement events это события в которых учитываются результаты спекулятивно выполненных команд, например при неверном предсказании перехода процессор может успеть выполнить несколько команд из неправильной ветви, эти команды потом будут отброшены процессором, но будут учитываться счетчиками. В противоположность этому, события типа At-retirement events считают только то, что процессор должен был бы выполнить в соответствии с программой.
Также свои нюансы имеются и при считывании счетчиков: процессор поддерживает «быстрое» считывание счетчиков. Если старший бит ECX равен 1, при выполнении команды RDPMC, то процессор возвращает только младшие 32 бита счетчика в EAX, при этом EDX не затрагивается.
Если же старший бит ECX=0, то все происходит как обычно – кроме EAX в младшем байте EDX возвращается 5-ый байт 40-битного счетчика.
Мониторинг HyperThreading.
В случае поддержки процессором этой технологии, имеются средства раздельного мониторинга для каждого из виртуальных процессоров. В этом случае регистры ESCR и CCCR имеют несколько другой формат.
Через биты T0_x и T1_x выбирается режим каждого из виртуальных процессоров.
В регистре СССR также появилось поле Active Thread которое ранее было зарезервировано.
Это поле служит для выбора активного потока для мониторинга:
00 – Считать только когда оба логических процессора неактивны.
01 – Только если один из двух (только один) логический процессор активен.
10 – Счет только если одновременно оба логических процессора активны.
11 – Счет если любой логический процессор или оба активны.
Именно поэтому в ранних процессорах Pentium 4 туда надо было писать 11b. Дело в том, что HyperThreading присутствовала в ядре всех Pentium 4 с самого начала, начиная с процессора Willamette, присутствует она и в Celeron. Но, по каким-то причинам (какие-то технические проблемы, либо маркетинговые соображения) второй логический процессор был отключен. Но так как вся остальная структура процессора не подверглась изменениям, то наличие «убитого» второго процессора необходимо учитывать и в случае если процессор не поддерживает HT.
Биты OVF_PMI_Tx управляют, какому из логических процессоров будет направлено прерывание PMI (Performance Monitoring Interrupt).
Список событий для процессоров архитектуры NetBurst можно найти в приложении к статье.
Вообще здесь была рассмотрены только основы мониторинга под Pentium 4. Процессор предоставляет еще много средств мониторинга, есть специальные MSR для использования дополнительных возможностей мониторинга. Рассматривать это все здесь значит превратить мануал из «Процессор изнутри» в «Pentium 4 и другие». Возможно, если данная тема вызовет интерес читателей, в следующих частях рассмотрим Event tagging и прочие специальные вопросы.
Processor spy.
Я использовал только счетчики с четными номерами, иначе нужно было бы отслеживать зависимости по ESCR что прибавило бы работы. Тем более что и этих 8 счетчиков хватает с лихвой; даже суперсовременный AMD Opteron обходится всего четырьмя, поэтому вопрос о нечетных счетчиках оставим на следующий раз.
Каждая пара счетчиков использует одинаковые события, так сделано в самом процессоре – счетчики 0 и 2, 4 и 6, 8 и 10 и т.д. используют одинаковый список ESCR-ов.
Через поле HT control можно задать для какого из логических процессоров производится счет.
Чтобы максимально обобщить программу по отношению ко всему семейству NetBurst я оставил только те события, которые поддерживаются всеми Pentium 4, от Willamette до Prescott.
Еще на программу повлияло отсутствие базы для тестирования – если с поиском P6 всех видов не было никаких проблем, то найти всех представителей NetBurst (включая Pentium 4 EE, HT, Xeon) не удалось.
Файлы: pentium4.zip, netburst.zip © Dark_Master
Процессор изнутри. Часть 2: INTEL NetBurst
Дата публикации 10 фев 2005