Процессор изнутри. Часть 1: INTEL P6 FAMILY — Архив WASM.RU
В данной части мануала подробно рассмотрим процессоры семейства P6. Следует сказать, что все, что мы тут будем обсуждать, относится не только к процессорам, упомянутым в названии, но и ко всем Celeron образованных от тех процессоров путем «урезания», так как микроархитектура у них у всех одна и та же.
Интерфейс процессора.
В таблице приведено описание сигналов системной шины процессоров P6. Эти сигналы составляют интерфейс процессора и системы и называются GTL+. Информация взята из документации по чипсету SIS630. Именно этот чипсет был выбран потому, что он состоит из одной микросхемы и таким образом, весь интерфейс процессора и чипсета приводится в описании северного моста. В других чипсетах нужно было бы отдельно составлять таблицы для интерфейса процессора с северным и южным мостом.
Подробного описания сигналов не дается, так как это не есть задача данного раздела, тут нужно только пояснить, зачем нужны некоторые сигналы, события на которых можно считать через счетчики производительности, остальные приводятся просто для полноты картины. Символ # после названия сигнала означает инверсию сигнала. До уровня схемотехники мы спускаться не будем, так что оставим это без объяснения, в двух словах это значит что активный уровень сигнала – низкий.
CPUCLK
Синхронизация, тактовые импульсы шины.
ADS#
Строб адресных линий, указывающий на начало новой транзакции, вводится инициатором этой транзакции. По этому сигналу начинается слежение (см. ниже) и другие операции связанные с новой транзакцией.
HREQ[4:0]#
По этим линиям процессор указывает тип производимой транзакции.
BREQ0#
Запрос на владение шиной.
BNR#
Запрос на блокировку следующей транзакции, вводится любым устройством, когда оно не может воспринять следующую транзакцию.
HLOCK#
Блокировка шины на время транзакции.
HIT#
Указывает на кэш-попадание для текущего адреса.
HITM#
Данный сигнал формируется как результат слежения и указывает процессору на попадание в модифицированную строку (см. ниже) кэша.
DEFER#
Сигнал указывает, что исходный порядок транзакций не гарантируется. В большинстве чипсетов этот сигнал не используется.
RS[2:0]#
Эта линия управляется устройством ответственным за завершение транзакции. Через эти линии оно сообщает о своем состоянии.
HTRDY#
Управляется приемником данных для указания на готовность к приему.
DRDY#
Источник данных устанавливает эту линию в активное состояние, когда данные на шине достоверны.
DBSY#
Сигнал указывает на занятость шины при неактивном DRDY#
BPRI#
Более приоритетный запрос на владение шиной, чем BREQ0#, используется для арбитража запросов со стороны нескольких устройств (процессоров).
CPURST#
Сброс процессора.
HA[31:3]#
Шина адреса. (В данном чипсете не поддерживаются 36-битные физические адреса, поэтому старшие разряды HA[35:32] обнулены, вообще же, процессоры семейства P6 поддерживают 36-битный физический адрес).
HD[63:0]#
Шина данных.
FERR#
Ошибка сопроцессора.
IGNE#
Игнорировать исключения сопроцессора.
NMI
Немаскируемое прерывание.
INTR
Маскируемое прерывание.
CPUSLP#
Перевод процессора в состояние Sleep.
STPCLK#
Подается на процессор в случае возникновения определенных событий, которые программируются через регистры чипсета. Используется для управления энергопотреблением.
SMI#
Вход в режим SMM.
INIT#
Инициализация шины.
A20M#
Маскирование старших разрядов адреса. Нужен для совместимости с 8086. Этим сигналом управляет Gate A20.
Это, разумеется, только те сигналы которые соединяют процессор и северный мост, еще есть сигналы питания, энергопотребления и прочее.
Для того чтобы, например, выбрать что-то из памяти, процессор выставляет запрос BREQ0#, и получив через некоторое время шину в свое распоряжение устанавливает DBSY#, чем запрещает другим процессорам что-то предавать или принимать. Затем процессор указывает адрес на линиях HA[31:3]# и тип транзакции на линиях HREQ[4:0]#. Потом он вводит ADS# и начинается транзакция обращения к памяти по чтению. Чипсет, точнее, его часть реализующая интерфейс с процессором определяет тип транзакции, и определив что это транзакция обращения к памяти передает адрес контроллеру памяти, который преобразует адрес в физические адреса на планке (не путать с физическими адресами процессора) и обращается к памяти по шине Memory bus.
Когда данные получены из памяти, и никаких ошибок зафиксировано не было, северный мост передает считанные данные на линии D[63:0]# и вводит сигнал DRDY#. Получив DRDY# процессор понимает что данные на шине достоверны, и принимает их с линий HD[63:0]#. После того как данные приняты, процессор снимает DBSY#. На этом одна транзакция завершается.
Транзакции могут накладываться друг на друга образуя конвейер (например, один процессор запрашивает данные, используя A[31:3]#, а второй получает ранее запрошенные данные через D[63:0]#, в следующем такте шины они меняются ролями, первый получает считанные к этому моменту данные, а второй запрашивает следующие. HLOCK# нужен для предотвращения такого «накладывания». Он нужен, если процессоры должны обращаться к каким-либо данные строго по очереди. Например, доступ к семафорам, в многопроцессорной системе, должен быть организован именно таким образом.
Такая организация шины называется шиной с расщепленными транзакциями (split transactions).
Кэширование.
В процессорах семейства P6 применяется разделенный кэш L1 для команд и для данных. Кэш L2 – общий, 4-ассоциативный. Длина строки всех кэшей – 32 байта.
L1 для кода входит в состав блоков выборки команд. L1 для данных называется DCU (Data cache unit) и используется исполнительными устройствами.
Кэш L2, для процессоров на ядрах Klamath, Deschutes, Katmai, внешний и расположен на процессорном картридже (эти процессоры используют разъем SLOT 1). Обращение к нему производится по отдельной шине (см. ниже).
Для процессоров на ядрах Mendocino, Covington, Coppermine, Tualatin (разъем Socket 370) кэш L2 расположен на кристалле ядра. С точки зрения ядра это роли не играет – все равно обращение к L2 происходит по отдельной шине. Зато эта шина полностью расположена на кристалле и работает на полной частоте процессора в отличие от кэша слотовых процессоров, где кэш L2 работает на половине частоты ядра.
Размеры кэшей:
- Data-L1 и Instruction-L1 = 8 или 16Кб
- L2 = от 0 в процессоре Celeron (Deschutes) до 2Мб в процессорах Хeon.
TLB.
Применяется одноуровневая схема TLB. Буфер разделен на отдельные буферы для страниц кода и страниц данных, которые, в свою очередь, разделены на буферы для стандартных страниц в 4Кб и для больших страниц - 2 или 4Мб.
Мультипроцессорная когерентность кэша.
Так как процессор P6 может являться частью многопроцессорной конфигурации необходимо обеспечить мультипроцессорную когерентность кэш-памяти (когерентность кэша – согласованность содержимого кэша и памяти), для соответствия этому требованию процессоры intel реализуют протокол MESI.
Строка кэша может находиться в одном из 4-х состояний:
1) Modified – строка находится в кэше только этого процессора и модифицирована (отличается от содержимого оперативной памяти по этому адресу), запись в эту строку не приведет к циклу обращения в память.
2) Exclusive – Строка присутствует в кэше только этого процессора и не модифицирована (ее копия в памяти действительна). Запись в эту строку переведет ее в состояние Modified без обращений в память.
3) Shared – строка присутствует в кэше не только этого процессора, ее копия в памяти действительна. Запись в такую строку должна сопровождаться записью в память, что вызовет перевод этой строки в других кэшах в состояние Invalid.
4) Invalid – строка недействительна.
Этот протокол реализуется только со стороны кэшей данных (L2 и data-L1), поскольку в кэш инструкций запись не допускается, у него нет проблем с когерентностью. Если программа делает попытку записи в адреса, кэшируемые в instruction-L1, процессор понимает, что он имеет дело с самомодифицирующимся кодом.
Все процессоры подключенные к шине Host bus следят за циклами обращения в память (они это делают в так называемых циклах слежения – snoop cycle, эти циклы инициируются внешней по отношению к процессору системой - чипсетом) со стороны других процессоров (и Bus master контроллеров) и обновляют состояние своих кэшей. Если контроллер кэш-памяти 2 уровня видит запрос на запись ячейки, копия которой есть в его кэше, со стороны другого процессора – он переводит строку в состояние Invalid. Аналогично, если процессор видит обращение по чтению к Modified-строке, инициированный другим процессором цикл обращения в память прерывается текущим процессором (с помощью HITM#), и им же генерируется write-back выгрузка содержимого строки в память, после этого другой процессор возобновляет попытку чтения и получает верные данные. Запись в Exclusive-строку переводит ее в состояние Modified без обращений в память. Запись в Shared строку приводит к сквозной записи в память (это повлечет перевод копий этих строк в других кэшах в состояние Invalid).
Пакетные циклы.
Информация в кэше хранится строками, которые занимают несколько байт. Флаг состояния строки относится ко всем ее байтам. Отсюда вытекает необходимость записывать в память строки кэша целиком. Для ускорения этой операции предназначен пакетный режим передачи (Burst transfer mode) когда процессор начинает пакетную передачу, адрес пакета передается только один раз, в начале цикла, следующие адреса вычисляются из первого по следующей таблице.
Первый адрес
Второй адрес
Третий адрес
Четвертый адрес
00h
08h
10h
18h
08h
00h
18h
10h
10h
18h
00h
08h
18h
10h
08h
00h
«Первый адрес» это младшие 5 битов физического адреса (с учетом того что младшие 3 бита всегда равны нулю), они могут принимать только значения описанные в таблице.
Передач именно 4 потому что строка кэша – 32 байта, шина данных – 64 бита (8 байт), чтобы передать строку кэша нужно 4 транзакции.
Пример обращения к кэшу.
Рассмотрим пример кэширования адреса 1234ABCD8h, в двоичном виде он выглядит так:
0001 0010 0011 0100 1010 1011 1100 1101 1000
Младшие 5 битов равны 11000 (18h) это и есть «первый адрес».
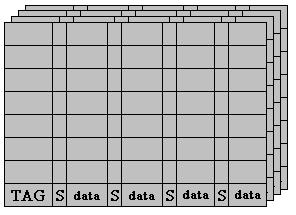
Предположим, что размер кэша 256Кб, и он содержит 4 строки в наборе и 32 байта в строке, то есть он может содержать (256*1024)/32=8192=2^13 строк объединенных в наборы по 4 штуки. Таким образом, кэш содержит 8192/4=2048=2^11 наборов строк. Получаем, что размер поля Index равен 11 битам. Так как одна строка вмещает 32 байта то размер поля OFFSET=5 битов. Оставшиеся 36-11-5=20 бит это и есть тег (TAG) строки.
Наш адрес имеет значение Index равное 10111100110 ((биты с 5 по 10 адреса) 5E6h, 1510d) и претендует на место в 1510-ом наборе из 2048-и.
Процессором инициируется пакетный цикл обращения к памяти по чтению.
Затем, после получения из пакетного цикла всех 32 байт, одна из 4-х строк 1510-го набора (какая именно определяет алгоритм замещения) замещается нашей строкой. В поле TAG помещается значение 0001 0010 0011 0100 1010 (1234Ah), а флаг состояния устанавливается в Exclusive (строка есть в кэше только этого процессора и действительна).
Теперь рассмотрим, как происходит обращение по чтению, скажем, по тому же адресу 1234ABCD8h.
Процессор препарирует этот адрес аналогично тому, как это делали мы, и определяет оттуда Index=1510. В кэше ищется этот набор, после чего параллельно по всем 4 строкам набора сравнивается поле TAG с тегом нашего адреса. В одной из строк обнаружено совпадение, процессор смотрит флаги строки, в нашем случае там Exclusive, что указывает на то, что данные достоверны, далее, процессор понимает, что ему не нужно обращаться в память, и с помощью поля Offset определяет, что ему нужен 24-ый байт в строке. Требуемый байт передается на внутреннюю шину данных.
Обращение по записи происходит аналогично. Единственное отличие заключается в следующем: если разрешена политика WB для данного участка памяти то процессор, определив нужный байт в кэше, пишет значение в кэш, после чего устанавливает флаг строки в состояние Modified и эта строка становится кандидатом на выгрузку в память в результате ее замещения другой строкой. До того как это произойдет, содержимое памяти и кэша по этому адресу отличается.
Процессоры P6 также поддерживают регистры MTRR с помощью которых можно задавать конкретные параметры кэширования для определенных участков памяти, а также атрибуты страниц PAT. Рассмотрение всего этого выходит за рамки данного мануала, который посвящен мониторингу производительности.
Ядро.
Для начала посмотрим на блок-схему процессора Pentium Pro.
Эту же архитектуру, с незначительными отличиями (отличия заключаются в том, что старшие процессоры имеют блоки MMX и XMM в составе исполнительных устройств) имеют и Pentium 2 и Pentium 3 и все разновидности Celeron (Celeron на ядре Deschutes не имеет кэша L2).
Из рисунка видно, что данные, через блок шинного интерфейса, могут быть получены либо из памяти, либо из кэша L2 использующего отдельную шину. Причем обращение и к памяти и к кэшу может идти параллельно. Это и есть торжественно объявленная Intel DIB (Dual Independent Bus) – двойная, независимая шина.
Рассмотрим подробно, как все это работает.
Выборка и декодирование.
На начальном этапе выполнения команды IFU обращается к кэшу инструкций L1, который входит в его состав, по предварительно вычисленному физическому адресу команды. Если нужных данных там нет - фиксируется промах-L1, далее, IFU обращается к устройству шинного интерфейса, BIU выполняет опрос кэша L2, если и там нужных данных нет – фиксируется промах-L2 и формируется запрос к оперативной памяти. Анализ L2 и обращение к памяти начинаются одновременно, если в L2 строка есть – цикл обращения к памяти прерывается.
После того как команды по нужному адресу были выбраны в кэш L1, устройство выборки считывает оттуда 32 байта и передает в декодер.
Декодеру (реально существуют 3 декодера, которые работают параллельно) передается просто последовательность из 32 байт, границы между командами определяются уже на этапе декодирования. Декодер, с помощью планировщика микроопераций, разбивает команды x86 на последовательности микроопераций, которые могут быть выполнены исполнительными устройствами.
Обычно команда включает в себе не более 4-х микроопераций, но некоторые сложные команды могут включать и больше.
Код операции, выбранный из памяти является ключом поиска (в простейшем случае это просто индекс микрооперации) во внутренней таблице микрокода, такое преобразование нужно потому, что микрооперации обычно намного больше по размеру, у них больше поля операндов и присутствуют специальные поля для управления физическими сигналами АЛУ. Использование микрокода позволяет уменьшить размеры программных команд т.к. размерность индекса массива (программного кода операции) может быть меньше элементов массива (микрооперации).
На этапе декодирования происходит прогнозирование ветвления.
Механизм прогнозирования работает так: существует таблица целевых адресов переходов BTB (Branch Target Buffer), она реализована аппаратно внутри процессора, при обработке условных переходов таблица обновляется. Строка в теории должна выглядеть примерно так:
BRANCH LINEAR ADDRESS
BRANCH TARGET ADDRESS
PREDICTION
Когда встречается новый условный переход, его линейный адрес заносится в первое поле, целевой адрес – во второе, а поле предсказания устанавливается в соответствии с результатом статического предсказания (все переходы «назад» произойдут, а «вперед» - нет).
Поле PREDICTION имеет размер в 2 бита. Для него определены следующие значения.
00 – Очень большая вероятность что переход не произойдет.
01 – Большая вероятность что переход не произойдет.
10 – Большая вероятность что переход произойдет.
11 – Очень большая вероятность что переход произойдет.
Когда добавляется запись в BTB, если направление перехода – «назад» - предсказание устанавливается в 10, если «вперед» - 01.
Если потом переход реально произошел – значение инкрементируется, если же переход не произошел – значение декрементируется. Для счетчика используется арифметика с насыщением – если к 11 нужно прибавить 1, то содержимое счетчика не меняется, аналогично, если там 0 и отнимается 1 то значение также остается тем же.
Когда блок выборки выбирает очередную команду, он смотрит, нет ли ее адреса (линейного) в BTB, если есть – команда является командой условного перехода. Далее из таблицы выбираются биты предсказания, на основании которых выборка продолжается либо по старому адресу (если предсказание – перехода не будет), либо по адресу загруженному из поля BRANCH TARGET ADDRESS (в случае если предсказание – переход будет).
BTB, по сути, является обычным наборно-ассоциативным кэшем. Только кэширует этот кэш не данные, а предсказания ветвлений.
Диспетчеризация и исполнение.
На данном этапе информация, известная из мануалов, заканчивается. Каждый из авторов описывает этот момент по-своему. Intel не раскрывает подробности реализации динамического исполнения, поэтому точно сказать как работает процессор я не смогу. Существует около десятка различных реализаций которые подходят под вышеприведенную блок-схему. Тем не менее, я опишу, как происходит процесс с моей точки зрения. Именно с моей точки зрения.
Поскольку, согласно блок-схеме, выполнение микроопераций из ROB невозможно (нет связей с исполнительными устройствами), то единственное место, откуда их можно выполнять – reservation station. Это прекрасно согласуется с блок-схемой.
После выполнения микрооперации попадают в ROB. Из ROB могут только восстанавливаться выполненные микрооперации. Если принять во внимание тот факт, что у Агнера Фога пишется, что при прохождении через RAT микрооперации читают регистры, (это значит, что они читают регистры еще до того, как они начинают исполняться), то один из возможных случаев, когда микрооперации читают регистры во время своего декодирования – хранение операндов микрооперации в самой микрооперации.
Если принять это за аксиому, то процессор реализует неупорядоченное исполнение следующим образом: после декодирования микрооперации проходят через RAT, где определяется регистр, который в текущий момент соответствует операнду микрооперации, и его значение заносится в поля операнда в самой микрооперации. Затем, поток микроопераций попадает в reservation station. Устройство диспетчеризации в произвольном порядке исполняет микрооперации находящиеся на Reservation station. После выполнения они попадают в ROB, где определяется микрооперация, которая должна быть выполнена в соответствии с программным кодом (восстановление происходит упорядоченно, в отличие от выполнения), результат этой микрооперации переписывается в постоянные регистры, после чего микрооперация удаляется из ROB.
Кратко опишу процесс по официальному мануалу.
Микрооперации из декодеров поступают в переупорядочивающий буфер и в резервационную станцию, ROB, вместе с таблицей RAT реализует спекулятивное исполнение. Микрооперации выполняются не в программном порядке, а в соответствии с готовностью операндов. Временные результаты сохраняются в ROB.
После того как микрооперации выполнены, они могут быть восстановлены и их временные результаты переписываются в постоянные регистры.
Если в программе встречается условный переход, процессор прогнозирует его и продолжает исполнение по предсказанной ветви еще «задолго» до того как EIP укажет на этот переход.
Этот процесс, выполнения команд до того как стало известно нужны ли они вообще, как уже говорилось в предыдущей части, называется спекулятивным выполнением. Если переход был предсказан неверно, процессор аннулирует результаты всех выполненных спекулятивно инструкций. Говоря простыми словами – удаляются все микрооперации в Reservation station и ROB которые, были выбраны после команды условного перехода. Как процессор определяет, какие были выбраны до, а какие после перехода? В литературе говорится что для этого используются временные метки для каждой микрооперации. Эти же метки используются для восстановления исходной последовательности команд.
Если развивать тему дальше, то можно понять, зачем при попытке записи в Time Stamp Counter записываются только младшие 32 бита, а старшие принудительно обнуляются: это сделано для того, чтобы туда (в старшую часть) нельзя было записать 0xFFFFFFFF и через небольшое время вызвать переполнение счетчика и нарушение последовательности микроопераций (в этом случае дикие глюки гарантированы, вроде исполнения по неправильной ветви перехода или использования командой чужих операндов). Кто-то может возразить, что обнуление счетчика программно эквивалентно его переполнению, но если вспомнить что обнуление может быть произведено только командой WRMSR, которая вызывает сериализацию (см. ниже) и очистку Reservation Station и ROB (после этого новые микрооперации начнут поступать уже с новым time stamp и все будет по прежнему), то становится ясно, что в процессоре все продумано до мелочей, и что интеловские инженеры недаром едят свой хлеб.
Восстановление последовательности (retirement).
Восстановление команды включает в себя запись временного значения в ROB в постоянный регистровый файл RRF, освобождения строки буфера и удаление микроопераций с резервационной станции. После того как проведено восстановление команды, ее уже нельзя отменить.
Операция восстановления к тому же является единственным способом записи в постоянные регистры (которые переименовываются). Любые команды, которые пишут в регистры (прямо или косвенно) пишут все во временные регистры, в постоянные регистры значение попадает только при выгрузке из буфера выполненной команды.
Увеличение EIP на длину команды производится именно на этапе retirement, реально выполнено несколько десятков команд, которые идут дальше по программе.
Процессор пытается «бежать впереди паровоза» выбирая и исполняя команды до того, как стало известно нужны они или нет. Если они оказались в правильно предсказанной ветви перехода, то процессору остается сделать только их восстановление.
Если же команда, которая должна быть выполнена в соответствии с программой, еще не готова – выдача следующей команды задерживается (при этом исполнительные устройства продолжают интенсивную работу с теми командами, которые находятся на резервирующей станции и готовы к исполнению).
Если какая либо команда вызывает исключение или сериализацию (сериализацией процессора (processor serialization) по команде называется завершение всех инструкций, предшествующих данной инструкции в программе, только после этого исполнение будет продолжено) - сначала восстанавливаются все команды предшествующие ей, после чего и возникает исключение. Cериализацию вызывают инструкции WRMSR, INVD, INVLPG, CPUID, LGDT, LIDT, IRET и некоторые другие. Этим гарантируется соответствие процессора архитектуре с «точными исключениями» суть которой в том, что при возникновении исключения гарантируется, что ни одна команда после команды генерирующей исключение не восстановлена к моменту исключения (хотя на практике на резервирующей станции обычно находятся несколько выполненных (но не восстановленных) команд следующих после команды вызывающей исключение).
Команды, находящиеся на резервирующей станции, могут выполняться в любом порядке, архитектура гарантирует, что результат исполнения будет таким же, как если бы команды исполнялись упорядоченно.
Переупорядочивание обращений в память.
Процессор должен обеспечить порядок внешних транзакций с памятью в соответствии с программой (если выбрана соответствующая политика), в то же время команды исполняются неупорядоченно, команда, пишущая в память на самом деле сначала пишет свое значение в этот буфер. Запись значения в память из буфера может откладываться процессором с целью оптимизации исполнения общего потока команд.
Использование буфера в общем случае зависит от выбранной политики записи (она программируется через регистры MTRR). В случае некэшируемой памяти порядок транзакций всегда строгий (совпадает с программой), в иных случаях возможно нарушение порядка операций с памятью (например, запись двух соседних слов может вызвать одну транзакцию записи двойного слова, а не 2 транзакции записи слова).
Мониторинг производительности.
Вопрос о программировании счетчиков на мониторинг определенного события относится уже к модельно-зависимому уровню архитектуры.
Процессоры P6 имеют 2 счетчика производительности, каждый из которых имеет свой управляющий регистр.
Регистры управления счетчиками это MSR с номерами 186h и 187h. Их формат следующий:
Поля Unit mask и Event select служат для программирования счетчиков на определенное событие (см. ниже).
USR – если бит установлен – счет происходит только если CPL=1,2,3
OS – если установлен, счет происходит только если CPL=0
Если установлены оба бита – счет не зависит от уровня привилегий, учитываются все события.
Бит EN есть только у счетчика 0. Его значение действует на оба счетчика.
INV – признак инверсии маски (см. ниже).
INT и PC предназначены для управления внешними выводами и прерываниями по переполнению счетчика, мы их использовать не будем.
Бит E (Edge detect) – позволяет определить время нахождения в каком-либо состоянии. Мы также не будем его использовать.
Маска счетчика применяется так, если она не равна нулю – если за такт произошло событий больше чем значение маски – счетчик увеличивается, в противном случае не изменяется. С помощью бита INV условие инвертируется – если за такт произошло событий меньше чем значение маски, счетчик инкрементируется.
Перед тем как использовать счетчики их нужно предварительно обнулить. Сами счетчики – MSR с номерами C1h и C2h.
Обнуляются они такой вставкой:
Код (Text):
К мануалу прилагается P6.htm, в котором находится таблица событий для процессоров P6. Сразу приношу извинения за возможные баги с форматом таблицы - как Acrobat скопировал, так я их в Word и вставил, не было времени поправлять все.
При считывании счетчиков нужно обязательно явно обнулять части EDX старше 40-го бита. Дело в том, что счетчики как-то связаны со счетчиком тактов – при считывании в старших частях возвращается старшая часть счетчика тактов. Почему так происходит – неизвестно, но это факт.
Processor spy.
К мануалу также прилагается программа из пакета Processor spy для мониторинга производительности под процессоры P6.
Через ComboBox-ы выбирается события и режим мониторинга. TrackBar над кнопками выбирает частоту считывания счетчиков (и скорость обновления графика). На графике отображается только то, как частота возникновения событий меняется со временем. Масштабирование графика осуществляется динамически по мере изменения максимального и минимального отображенного а нем значения.
Кнопки Start и Stop действуют на оба счетчика одновременно, т.к. в процессорах intel бит Enabled есть только и счетчика 0 и разделяется между счетчиками.
Сама программа и ее исходники (на C++ Builder 6.0 (вот ересь-то! - прим.ред.)) прилагаются к статье. Программа является полностью Freeware и Open Source. Для доступа к MSR-регистрам используется драйвер, рассмотренный в первой части.
© Dark_Master
Процессор изнутри. Часть 1: INTEL P6 FAMILY
Дата публикации 3 фев 2005