Основы разработки антивирусного сканера — Архив WASM.RU
Содержание
- Введение
- Простейшие типы вирусов
- Методы детектирования
- Контрольные суммы и технология их расчета
- Использование контрольных сумм для детектирования вирусов
- Алгоритм поиска файлов
- Основы построения вирусной базы
- Основы работы с вирусной базой
- Заметки по лечению вирусов
- Заключение
1. Введение
В этой статье речь пойдет о разработке примитивного антивирусного программного обеспечения, точнее сказать антивирусного сканера.
Сканнерами называют программы, которые проверяют файлы на предмет зараженности их известными программе вирусами.
Прочитав эту статью, я не гарантирую, того, что вы в тот же момент станете умнейшим вирусным аналитиком, эта область программирования достаточно необычна и тяжела для понимания. Сталкиваясь с ней (областью) «вплотную» в первый раз очень тяжело сразу «взять быка за рога». Но в этой статье я попытаюсь изложить основы, так что вполне возможно, то, что будет описано ниже вы, уже знали.
Прежде чем читать статью, необходимо удостовериться, что ваш уровень знаний ассемблера не ограничивается умением писать красивые интерфейсы и менюшки, в антивирусных программах это не главное. Конечно без удобного (дружелюбного) интерфейса ваша разработка не будет востребована. Но все же, необходимо иметь некоторые понятия о:
- Контрольные суммы участков данных, что это такое и примерный алгоритм расчета
- Вирусы и троянские кони в бинарных файлах (исполняемых файлах), а так же написанные на скриптовых языках (VBS, JavaScript)
- Методы работы с файлами (поиск, запись, чтение и тд)
2. Простейшие вирусы
Вирус – программа очень маленьких размеров, основной задачей которой является распространение по компьютерам пользователей, за счет различных хитрых алгоритмов и ошибок пользователей.
Вирусы это очень сложные программы, их можно разделить на множество видов, но мы ограничимся всего двумя. Разделим вирусы на простейшие и файловые вирусы. Файловые вирусы это те, которые умеют заражать файлы различных форматов (загрузочные – PE, документы, файлы помощи и еще множество других), обычно эти вирусы написаны на языке ассемблера, и для их обнаружения необходимо очень хорошо знать структуру файлов, которые они поражают. Под понятием простейших вирусов я подразумеваю различных червей и сюда же можно приписать троянских коней.
Файловый вирус – вирус, который распространяется через зараженные файлы различных форматов, обычно исполняемых. Т.е. кто-то кому-то передал программу, один из исполняемых файлов которой был заражен вирусом.
Червь – вирус, который распространяется самостоятельно (не поражая какие либо файлы), обычно через глобальные сети, путем рассылки себя в письмах; авторами червей часто являются хакеры и для своего распространения черви используют различные дырки в операционных системах.
Троянские кони – программы, у которых отсутствуют функции самостоятельного распространения (т.е. они распространяются различными людьми специально), но обязательно присутствуют различные деструктивные функции.
Деструкция – алгоритм, причиняющий вред компьютеру и пользователи, иногда не только моральный, но и материальный. Деструктивные алгоритмы часто используются в вирусах и всегда используются в троянских конях.
Деструкция в троянских конях – это алгоритмы, которые могут совершать различные пакости, начиная от форматирования жесткого диска или перезаписи flashbios и заканчивая воровством «важных» файлов (паролей для доступа в интернет) с компьютера пользователя.
3. Методы детектирования
Главное, что черви и троянские кони не умеют заражать другие файлы, по этому всегда распространяются в одном и том же виде. Т.е. в виде не изменяющегося файла. Допустим, у нас имеется файл с вирусом-червем, который занимает 10 килобайт. Червь распространяется в виде исполняемого файла PortableExecutable. Нам необходимо написать программу антивирус против этого червя.
- Программа будет искать PE-файлы в указанном каталоге
- Каждый найденный файл размером 10 килобайт и больше будет открываться
- Первые 10кб будут считываться, и сверяться с теми, которые были взяты из «тела» вируса
- Если содержимое будет совпадать, то значит перед нами червь и нужно его вылечить
Мы составили примитивный алгоритм детектирования вируса червя. Теперь допустим, таким способом ваша программа опознает, и лечит 100 вирусов. В качестве сигнатуры (данных, по которым определяется зараженность объекта тем или иным вирусом) используется полный вирусный код, допустим для каждого вируса по 10 кб. В результате вирусная база (база данных программы содержащая алгоритмы по детектированию и лечению вирусов) программы будет занимать 1 мегабайт, а это очень много. Крупнейшие антивирусные программы детектируют несколько десятков тысяч самых разнообразных вирусов, и их вирусные базы занимают всего несколько мегабайт.
Детектирование (обнаружение) вирусов, не изменяющих своей структуры, является примитивнейшим занятием. И так сигнатура для детектирования вирусов может занимать всего 3 двойных слова, т.е. 12 байт и быть очень надежной, если использовать контрольные суммы …
4. Контрольные суммы и технология их расчета
Контрольная сумма это 32 битное число (очень редко 16 битное), которое характеризует определенный участок кода. Есть множество способов подсчета контрольной суммы, для лучшего восприятия этого термина рассмотрим пример примитивнейшего подсчета:
Например, у нас есть участок кода, состоящий из 5 байт (десятичная система): 001 004 000 005 100
По нашему примитивному подсчету, контрольная сумма его будет равняться 1+4+0+5+100=110. Т.е. прочитав контрольную сумму другого участка, мы получим другое значение. Однако, используя столь примитивный алгоритм расчета, контрольные суммы совершенно отличающихся участков могут совпадать, для этого используются более продвинутые процедуры подсчета.
Комментарии к алгоритму расчета контрольной суммы (crc) отсутствуют потому, что достаточно понимать смысл подсчета crc, стандарта подсчета не существует, а описывать операции, производимые в этой процедуре достаточно тяжело и бессмысленно. Со временем будет появляться опыт в подобных вещах и если будет необходимо, то вы и сами разберетесь в коде.
5. Использование контрольных сумм для детектирования вирусов
Если необходимо подсчитать контрольную сумму участка в несколько килобайт, то это конечно не мгновенная процедура. Если считать контрольную сумму каждого найденного файла то процесс проверки не будет проходить так быстро как хотелось бы.
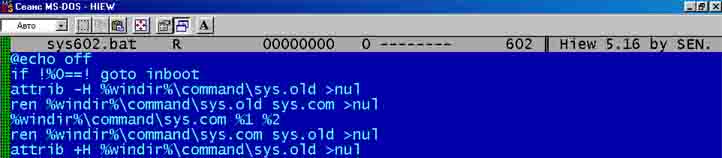
Возьмем в качестве примера вирус BAT.Sys.602, распространяющийся в виде файла BAT, написанного на примитивном языке Batch, входящим в комплект операционной системы DOS. Внешне вирус-червь представляет собой обычный текст.
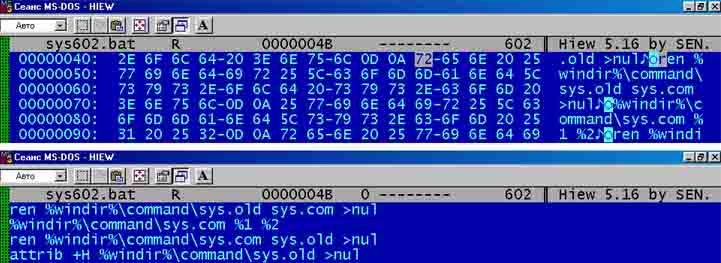
Для опознавания наличия этого вируса в BAT-файлах совсем не обязательно считать контрольную сумму всего вирусного кода, достаточно взять участок кода, состоящий из нескольких строк. Так же просто необходимо запомнить их расположение в вирусном файле и длину этих строк (всех вместе). Допустим, нам приглянулись строки 4 и 5.
Как мы видим, строка 4 начинается в файле со смещения 75 (4Bhex) и заканчивается 150 (96 hex). Т.е. размер двух строк составляет 75 байт.
Но брать в качестве сигнатуры определенные строки не совсем обязательно, можно взять любой кусок кода, размер желательно до 100 байт, что бы время на расчет контрольной суммы затрачивалось минимальное.
Вашему вниманию предлагается пример программы, которая считает контрольную сумму участка кода выбранного выше (смещение 75, длина 75 байт) в файле ‘sys.bat’ …
; прочитаем в “buffer” данные размером ; “crc32_code_len” изфайла ; закроемфайл
6. Алгоритм поиска файлов
Как вы уже, наверное, знаете для поиска файлов? используются API: FindFirstFile, FindNextFile, FindClose.
ПараметрамиFindFirstFile является маска для поиска и «место» под структуру для поиска (объявленную структуру официального типа или буфер, размер которого не меньше размера официальной структуры). Маской для поиска является обычная строка, содержащая путь к каталогу, в котором будет производиться поиск, а так же маску поиска (обычно используется “*.*”).
Вид официальной структуры для поиска:
Можно объявлять эту структуру, а можно использовать эквивалент “findbuf db 314 dup (?)”. Немного разбираясь в программировании можно догадаться, что имя найденного файла будет находиться по смещению 44 от начала findbuf.Используем “movesi,offsetfindbuf + 44” и регистр esi указывает на имя найденного файла или каталога.
После выполнения API FindFirstFile, регистр eax будет содержать идентификатор поиска или в случае ошибки –1.
Вызов FindFirstFile используется только один раз, далее в дело вступает FindNextFile. Параметрами этой апи являются идентификатор поиска (который мы получили от вызова FindFirstFile и должны были сохранить) и та же структура для поиска (которая так же использовалась при первом поиске). Поиск ведется до тех пор, пока регистр eax не будет равняться нулю.
Эти API ищут файлы или каталоги по маске поиска, т.е. нельзя искать только файлы или только каталоги. Когда используется маска ‘*.*’ то будут найдены все каталоги и файлы, содержащиеся в указанном перед маской каталоге.
Все конечно хорошо, но необходимо что бы наша антивирусная программа могла проверять файлы не только в указанном каталоге, но и в тех, что расположены ниже. Для этого мы должны писать рекурсивную процедуру, т.е. такую, которая умеет вызывать сама себя.
Прежде всего, необходимо объявить переменную для поиска в каталогах содержащих множество других подкаталогов. Думаю, что пользователей, у которых количество подкаталогов в каталоге превышает 50 единицы, по этому ограничимся этим числом. И так, для процесса поиска в каждом каталоге должны быть индивидуальными (не использоваться в других процессах) маска поиска (максимум 260 символов), идентификатор поиска (двойное слово, 4 байта), структура для поиска (318 байт) и флаг (размером 1 байт, а для чего нужен этот флаг, я объясню позже). В результате мы должны объявить переменную а/ля ”buf db ( ( 1 + 260 + 4 + 318 ) * 50 )”. Ячейка для каждого процесса поиска будет занимать 1+260+4+318 = 583 байта и одновременно может вестись 50 процессов (не более). Конечно, можно использовать память из стека, но это будет тяжелее объяснить.
Структура размещения данных в ячейке может быть такой, какая удобна вам.
Я предлагаю структуру такого типа:
Теперь поговорим о алгоритме поиска. Сначала необходимо обработать все файлы текущего каталога, а затем уже подкаталоги. Но API сначала находят подкаталоги, а потом уже файлы. Вот для этого и необходим флаг.
При первом поиске флаг настраивается только на поиск файлов, те если значение флага не совпадает с необходимым, то найденные каталоги просто пропускаются. По окончанию поиска флаг перенастраивается на поиск только каталогов, и теперь уже пропускаются файлы.
Давайте рассмотрим пример программы обходящей дерево каталогов в поиске всех файлов…
7. Основы построения вирусной базы
Данные необходимые для поиска и лечения вирусов обычно хранятся в вирусной базе. Ее формат может быть любым, стандартов не существует. Мы рассмотрим пример вирусной базы для детектирования скрипт вирусов, которая будет содержаться в исходном коде программы, а не в отдельном файле.
Вот мы имеем простейшую вирусную базу для трех вирусов. Размер одной вирусной записи (данных об одном вирусе, необходимых для его детектирования и лечения) в данном случае составляет 20 + 4 = 24 байта.
Если же вирусная база хранится в отдельном файле, то при старте антивирусный сканер должен загрузить ее в память, для того, чтобы к данным, хранящимся в ней, было быстрее и проще «обращаться» в необходимости. Для этого пишутся специальные процедуры разбора, ну и конечно же вирусные записи содержат гораздо больше данных, например таких как тип вируса, адреса процедур для детектирования и лечения … Но обо всем этом в следующий раз, в следующих статьях.
8. Основы работы с вирусной базой
В нашем случае, необходимо писать процедуру для работы с найденными файлами, т.е. читать данные из файла по смещению 75 и размером 75 байт, считать контрольную сумму и сравнивать по очереди с указанной во всех доступных (в нашем случае 2) вирусных записях в вирусной базе. Если совпадает, выводит информацию о том, что найденный файл заражен определенным вирусом.
Допустим, программа нашла файл, прочитала из него 75 байт по смещению 75 и подсчитала контрольную сумму этого участка. Контрольная сумма содержится в переменной “crc32_buf”. Вот как должен выглядеть процесс проверки на зараженность известными программе вирусами:
Код (Text):
Код (Text):
Код (Text):
Код (Text):
Код (Text):
Код (Text):
--------------------------------------------
Код (Text):
Код (Text):
Код (Text):
Код (Text):
9. Заметки по лечению вирусов
В данном случае найденные файлы с вирусами можно просто удалять, но это самые простейшие вирусы. Обычно каждый вирус изменяет что-то в файлах настройках операционной системы, пытается спрятаться от чужих глаз. Даже для вирусов, файлы носители которых (дропперы) можно просто удалять это (скорее всего) не будет являться сто процентным лечением. Необходим анализ алгоритма работы вируса, вполне возможно он уже (например) успел прописать свой вызов в WIN.INI из «потайного места». Так как эти типы вирусов не заражают файлов, то от них мог бы избавиться любой начинающий пользователь. Авторы таких вирусов знают это и для этого предпринимают разнообразные хитрые методы для того, что бы вирус мог выжить после «чистки», вернуться «к жизни» второй раз.
10. Заключение
Соответственно если Вы заинтересовались этой областью программирования, придется разбираться и изучать (хотя бы основы) множество скрипт языков программирования. Я не говорю про основы строения исполняемых файлов написанных не на ассемблере, а на языках высокого уровня. Как раз на них и пишется большинство троянских коней. Необходимо будет разбираться с различными упаковщиками и шифровщиками исполняемых файлов, строением архивов …
Все примеры программ, которые были представлены Вашему вниманию в статье, доступны в ZIP-архиве, но в немного измененном виде. Добавлен вывод «рабочей информации» через консоль и почти полностью отсутствуют комментарии к программе, но в статье комментариев изобилие.
Готовое подобие антивирусного сканера так же доступно, а так же прилагаются КУСКИ вирусных дропперов, которые вставлены в базу антивируса (которую мы рассматривали выше). Полный вирусный код я не представляю, так как в этом нет необходимости.
Если статья действительно кому-нибудь поможет, то я буду писать на эту тему еще … например про основы детектирования и лечения файловых вирусов, технологии анализа программного кода (кодо-анализаторов) и эмуляции программного кода (для детектирования полиморфных и шифрованных вирусов) …
Основы разработки антивирусного сканера
Дата публикации 24 дек 2003