Основные методы заражения PE EXE — Архив WASM.RU
- Introduction
- I. Внедрение в заголовок
- II. Расширение последней секции
- III. Добавление новой секции
- Conclusion.
Introduction
Существует множество методов заражения (то есть записи кода вируса в код программы без потери работоспособности последнего) файлов формата Portable Executeable. Есть простые методы, которые с лёгкостью отлавливаются антивирусами, есть очень навороченные, о которых я вам когда-нибудь может быть расскажу... Вполне может случиться так, что вы изобретёте свой собственный оригинальный способ и успеет пройти дня этак три прежде чем сотрудники Kaspersky Lab смогут его проанализировать и пополнить свои avc'шки парой-тройкой новых контрольных сумм...
Чтобы иметь хотя бы теоретический шанс сделать это, вы должны:
1) знать структуру PE;
2) уметь находить адреса API'шных функций по их имени;
3) assembler, assembler и ещё раз assembler, что бы там не говорили про него ортодоксы из rsdn'а.
4) разобраться с основными методами заражения PE, чем мы с вами сейчас и займёмся под моим руководством.Приведенные в статье исходники заточены под TASM32. Замечу жирным, что они не являются вирусами; и вообще - материал статьи предназначен исключительно для самообразования и в первую очередь ориентирован на любопытных программистов, интересующихся местом жительства этих зверушек. Те несколько строк, которые могут превратить вас из законопослушных исследователей программ в вирмейкеров - остаются на совести читателя и в данной статье не рассматриваются.
Хочу выразить благодарность людям, которые оказали неоценимую помощь при подготовке данного материала, а именно:
Serrgio
90210
Dmitri AlexeenkoА так же группам:
HI-TECH
WASM
TNTОднако, ближе к делу. Существует три основных метода заражения PE EXE:
1) внедрение в заголовок;
2) расширение последней секции;
3) добавление новой секции.
На этой оптимистической ноте надеваем белый халат, берём в руки скальпель и, вооружившись бинокулярным микроскопом, осторожно приоткрываем чашку Петри с копошащейся там заразой.I. Внедрение в заголовок.
Итак, рассмотрим первый метод заражения PE EXE файлов, а именно запись в заголовок жертвы. Он не самый простой, но довольно интересный, с него и начнём.
Если кому интересно, то небезызвестный вирус win95.CIH (Чернобыль) записывал свою загрузочную процедуру именно в то место, которое будет рассмотрено ниже. Мы пока что пойдем простым путем и запишем туда все тело нашего "вируса". Я надеюсь, у вас есть под рукой описание структуры PE заголовка, рекомендую почаще заглядывать в него с целью лучшего усвоения материала. Довольно неплохой труд у Hard'а Wisdom'а, хотя его статьи и имеют ряд неточностей. Для знающих английский язык, рекомендую описание PE от некого Luevelsmeyer.Прежде всего отмечу, что "запись в заголовок" - это не совсем верное утверждение, так как рассматриваемое пространство находится не в самом заголовке. Но для простоты изложения я позволю себе это допущение.
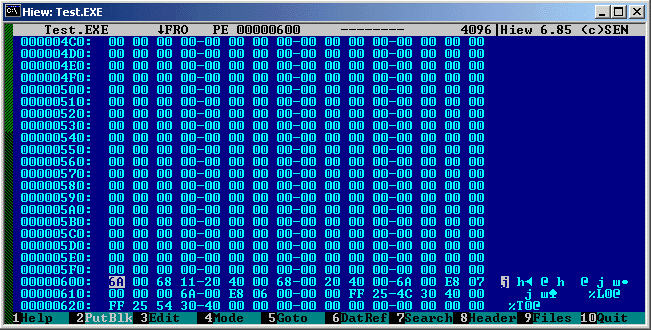
На нижеследующем рисунке изображена примерная структура PE EXE файла.Участок, помеченный голубым - это и есть "дыра" в которую мы запишем тело "вируса". Как видно из рисунка, она находится между последним элементом (element n) таблицы объектов и смещением первой секции.
Откуда же эта дыра взялась? Дело в том, что существует такое понятие, как выравнивание. За эту величину отвечает поле File Align в PE Header по смещению 3Ch и имеющее тип DWORD. В большинстве случаев оно равно 200h и это означает, что секции в файле должны быть расположены по адресам кратным данному значению. Большинство линкеров, выставляют физический адрес первой секции равным 600h, следовательно, первая секция располагается в файле по смещению 600h. Заголовок файла содержит намного меньше информации, чем 600h байт, вот и получается в результате "пробел" - чистый клочок бумаги, на котором мы можем написать всё, что пожелаем ;)Вот вам реальный пример:
Думаю, пояснений не требуется, из рисунка видно, что до смещения 600h присутствует свободное место.
Для того чтобы найти это свободное место необходимо:
1) узнать некоторые значения из PE Header;
2) узнать некоторые значения из Object Table;
3) произвести парочку нехитрых арифметических операций.Вот нужные нам поля из заголовка PE EXE файла:
PE Header:
RVA
Size
Name
Description
06h
Word
Num of Objects
Число элементов в Object Table
14h
Word
NT Header Size
Размер заголовка PE файла-18h
54h
DWord
Header Size
Общий размер всех заголовков
Почему в поле NT Header Size присутствует ("минус"18h)? Дело в том, что это поле показывает размер PE заголовка, начиная с поля Magic, которое находится по смещению 18h, следовательно, чтобы найти размер всего заголовка, необходимо прибавить смещение поля Magic.
Object Table:
RVA
Size
Name
Description
14h
DWord
Physical Offset
Физическое смещение секции относительно начала EXE файла
Теперь давайте подробнее рассмотрим действия, которые нам необходимо выполнить для поиска свободного места. В скобках даны пояснения, откуда берутся значения, из PE Header или Object Table.
1. Находим размер PE заголовка (PE Header)
2. Находим размер таблицы объектов, для этого:
a) берем количество элементов Object Table (PE Header)
b) умножаем на размер одного элемента, т.е. на 40
3. К виртуальному адресу (далее VA) файла–жертвы прибавим сумму результатов вычислений первого и второго пунктов, получим VA искомой области.
4. Находим физическое смещение первой секции:
a) находим смещение первого элемента таблицы объектов, это конец заголовка PE и начало Object Table
b) получаем из этого элемента физическое смещение первой секции и добавляем к нему VA файла – жертвы
5. Вычислим разность результатов четвертого и третьего пунктов, получаем размер искомой областиА вот и сам код, который находит нужную "дыру" в заголовке:
Код (Text):
После выполнения этого кода в eax будет размер свободного места, а в esi его виртуальный адрес.
Увидели? Все просто и ясно. Теперь вам понятно, как можно заразить файл, не увеличивая при этом его размера?
Сейчас немного охлажу вашу радость. Не все так просто, вот явные минусы этого метода:
- "дыра" не резиновая, а следовательно и размер вируса ограничен.
- если вы поставите Entry Point на эту область, антивирусные программы это сразу заметят, т.к. они не любят, когда точка входа в программу указывает на заголовок. (Напомню, что Entry Point - точка входа в программу - находится в PE Header и имеет смещение 28h).С первым минусом бороться просто: возьмите любую статью, в которой рассказывается, как оптимизировать код по размеру и не поленитесь пробежать по своему исходнику. Есть мнение, что ресурсы современных компьютеров позволяют не принимать во внимание такую "мелочь", как размер программы, но наука под названием вирмейкинг придерживается на счёт этого несколько иного мнения.
Для борьбы со вторым минусом можете по оригинальной Entry Point вставить jmp на ваш код, сохранив затертые байты (байты, поверх которых запишется jmp на код вируса) и антивирусы, не смогут обнаружить вас по этому признаку, т.к. Entry Point не изменится.
Ну и еще пара моментов, которые могут доставить вам несколько "приятных" часов. Запись в данную область запрещена, так что ваш код (в заголовке жертвы) не сможет сохранять данные в свое тело, следовательно, можно забыть про глобальные переменные. Вот 3 выхода, которые позволят обойти это ограничение, рассмотрим вкратце, в чем они заключаются:
1. Используйте VirtualProtect на эту страницу. В SDK написано, что функция VirtualProtect изменяет режим доступа к требуемой области памяти для текущего процесса. Вот простенький пример:
Код (Text):
Более детальное описание функции смотрите в Platform SDK.
2. Можно воспользоваться оригинальным методом Z0MBiE, сущность которого заключается в изменении атрибутов страниц в таблице страниц. Этот метод позволяет производить запись даже в kernel из ring3! Однако у него есть один очень существенный недостаток - это работает только под win9X.
3. Чтобы не повторяться, я пошел другим путем, а именно отказался от всех глобальных переменных в своем вирусе и использовал только локальные (т.е. стековые) переменные. Кто читал мою статью по поиску API (доступна на www.wasm.ru), должен был заметить, что в исходнике нет глобальных переменных, все операции я проводил через стек.
Вы думаете это все?
Напрасно, жизнь низкоуровневого программиста тяжела, давайте поглядим на сам код.Он хоть и будет работать, но возможны некоторые баги. Почему?
Мы берем первый элемент в таблице объектов и считаем, что он описывает первую секцию. Это утверждение основано на том, что секции идут в порядке возрастания и первый элемент описывает первую секцию. Хорошо, если бы это всегда было так.
Однако в жизни всё намного сложнее: элементы и секции PE-файла могут идти в любом порядке. И если алгоритм вируса не предусматривает подобную ситуацию, то он может запросто уничтожить такой файл, что не есть хорошо.
Выход здесь такой: нужно найти элемент с наименьшим физическим смещением секции, это и будет смещение первой секции.
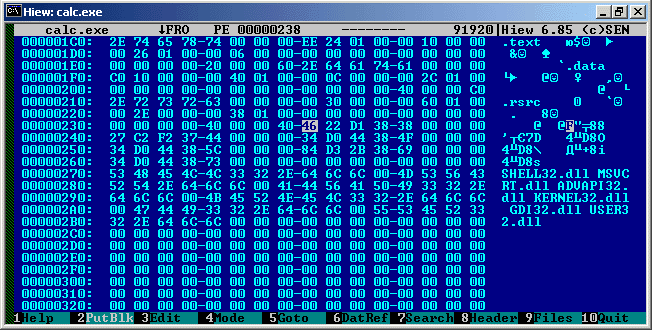
Это было первое наше "упущение". Второе заключается в том, что после последнего элемента Object Table и до rva=SizeOfHeaders, могут находиться так называемые Bound импорты. На картинке видно, что после последнего элемента Object Table есть еще «что то». В это и есть Bound импорты. Что это такое мы рассмотрим более подробно в третей части, пока просто посмотрите в исходнике как происходит проверка на их наличие и как их присутствие отражается на алгоритме поиска свободного места.Размер и RVA Bound импортов можно узнать из заголовка PE.
PE Header:
RVA
Size
Name
Description
D0h
DWord
Bound Import RVA
RVA Bound импортов
D4h
DWord
Bound Import Size
Размер Bound импортов
Код (Text):
Я думаю, не имеет смысла объяснять все подробно, ничего сверхъестественного в этом коде нет, просто мы находим первый элемент в таблице объектов и смотрим на физическое смещение секции, которую он описывает. Для начала мы принимаем это смещение за наименьшее. Далее находим второй элемент и сравниваем физическое смещение "его" секции с предыдущим, если оно меньше чем в первом элементе, то примем текущее за наименьшее и таким образом работаем в цикле столько раз, сколько у нас элементов. В итоге мы находим элемент в котором физическое смещение секции является наименьшим по отношению к другим элементам. Теперь можно утверждать, что этот элемент описывает первую секцию. Затем мы проверяем наличие Bound импортов, если обнаружено их присутствие, то добавим их размер к размеру PE Header и Object Table. Дальше все так же как и в первом примере.
Хочу сразу заметить, что данные примеры написаны не для того, чтобы их тупо передирали, а для объяснения самого принципа. Поэтому они не сохраняют содержимого регистров и имеют не самый оптимальный алгоритм. Я надеюсь, что вы разберетесь с этим и сделаете лучше, т.к. оптимизация кода выходит за рамки этой статьи.
Напоследок еще одна тонкость, в PE Header по смещению 54h находится DWord, который показывает общий размер всех заголовков, т.е. DOS Stub + PE Header + Object Table + Bound Imports. Это значение нужно сделать равным физическому смещению первой секции, т.е. мы как бы растянули заголовок до первой секции. Если этого не сделать, то загрузчик забьет нулями все, что находится между физическим смещением первой секции и общим размером заголовков. Таким образом мы потеряем часть "вируса".
Запись кода в заголовок показана в примере Example1-3.asm
II. Расширение последней секции.
Скажу сразу, что огромным минусом данного метода является то, что размер зараженного файла увеличится, а, следовательно, увеличится вероятность быть обнаруженным слишком дотошным пользователем (не говоря уж об антивирусах). Обойти это можно разными способами. Например, можно запаковать секцию или ее часть, а в высвобожденное пространство записать тело вируса и при передачи управления распаковывать секцию (тогда, кстати, не придется её расширять). Везде встречаются свои трудности и тонкости, я надеюсь рассмотреть впоследствии как можно больше технологий и способов.
Что ж, не будем тянуть и пойдем дальше...
Итак, в первой части мы уже сталкивались с таблицей объектов (Object Table) и ее элементами. Настало время познакомится с форматом ее элемента.Object Entry: = 28h bytes
RVA
Size
Name
Description
00h
8 байт
Object Name
Имя объекта (секции)
08h
DWord
Virtual Size
Виртуальный размер секции (в памяти)
0Ch
DWord
Section RVA
RVA секции (в памяти, относительно Image Base)
10h
DWord
Physical Size
Физический размер секции (в файле)
14h
DWord
Physical Offset
Физическое смещение (в файле, относительно его начала)
18h
12 байт
Reserved
В EXE не используется (для OBJ)
24h
DWord
Object Flags
Битовые флаги секции
Каждый элемент описывает одну секцию. В Object Table элементы идут последовательно друг за другом без промежутков, но необязательно в порядке возрастания Physical Offset и Section RVA. Т.е. последний элемент не всегда описывает последнюю секцию, хотя в большинстве случаев это так (под "последней секцией" я подразумеваю секцию, которая физически и виртуально находится в файле последней). При поиске свободного места в заголовке мы искали физическое смещение первой секции, т.е. секции, которая находится в файле первой физически (посмотрите ещё раз код из первой части). Здесь же нам понадобится физическое смещение последней и смещение элемента (из Object Table) ее описывающего - для того, чтобы пропатчить некоторые значения.
Найдем самое большое значение Physical Offset из всех элементов. Элемент, содержащий это значение, и будет нам нужен.
Так же нам понадобится найти элемент, который содержит наибольшее значение Virtual RVA. Объясню зачем это нужно… Дело в том, что секция может быть физически в файле последней, а вот виртуально, т.е. в памяти, она может расположиться где угодно, например первой. Тогда при ее расширении мы затрем последующую секцию в памяти. Вообще то я такого не встречал, наверное и линкеров таких нет, но вирус на то и вирус, чтобы предусмотреть все возможные варианты.
Затем нам нужно проверить, принадлежат ли наибольшие значения Physical Offset и Virtual RVA одному элементу, если да, то секция является последней и физически в файле и виртуально в памяти.
Код (Text):
Теперь мы можем дописать свой код в последнюю секцию и пропатчить элемент, который ее описывает.
Если вы прислушались моего совета и пользуетесь отладчиком, то в случае работы с TASM, должны были заметить довольно интересную вещь. Физический конец последней секции меньше размера файла!!!
Т.е. Physical Offset + Physical Size < File Size, как так, а что же содержится в оставшемся участке? В большинстве случаев ничего, просто нули, это называется оверлеем. Оверлей – это то, что находится между физическим концом последней секции и концом файла. Конечно, оверлей может содержать и полезную для файла информацию.
Вот пакет TASM, при компиляции, создает файл с пустым оверлеем, зачем он это делает для меня осталось загадкой. MASM и FASM такого не допускают, и файлы скомпилированные их линкерами имеют «нормальную» структуру.Теперь, наша задача определить является ли оверлей в жертве пустышкой, т.е. содержит нули или это оверлей содержащий какую либо информацию для жертвы. Поясню на примере…
Код (Text):
Кстати, если найден оверлей-пустышка, то с таким файлом можно проделать довольно интересную вещь. Когда размер кода, внедряемого в жертву, меньше размера пустого оверлея, то при записи нашего кода в файл, размер его не увеличится. Т.е. секцию мы расширим, а размер не увеличится.
В нижеследующем коде как раз и выполняются эти действия. Если физический конец последней секции больше размера файла, и разность между ними заполнена нулями, то количество байт для записи в файл мы не увеличиваем и оставляем равным размеру файла. Конечно, это происходит, если размер оверлея больше или равен размеру внедряемого кода.
Код (Text):
Да, чуть не забыл, после расширения секции, в PE Header нам тоже нужно кое-что изменить, смотрите:
PE Header:
RVA
Size
Name
Description
50h
DWord
Image Size
Виртуальный размер всего загружаемого образа
Просто к DWord по этому смещению нужно будет прибавить размер нашего кода. Это справедливо для примера Example2-1.asm, о втором примере читайте ниже.
Теперь еще один немаловажный момент, касающийся виртуального и физического размера секции.
Что такое виртуальный размер? Это то, сколько памяти отведет система для секции, а физический - сколько она занимает на диске. Здесь могут быть такие варианты:Virtual Size = Physical Size - идеальный вариант
Virtual Size > Physical Size - так строятся секции с неинициализированными данными
Virtual Size < Physical Size - бывает и так, загрузчик системы все равно загрузит такую секцию, т.к. он смотрит на Physical SizeПодытожим то, что необходимо сделать в простейшем случае:
1) находим смещение последней секции и ее элемента из Object Table;
2) записываем код "вируса" в конец последней секции (Physical Offset+Physical Size=конец секции);
3) увеличиваем физическую и виртуальную длины последней секции на длину "вируса";
4) увеличиваем размер загружаемого образа на длину "вируса";
5) при необходимости изменяем характеристики секции (битовые флаги);Необходимо учесть такой момент, если у расширяемой секции физическая длина равна 0, то эту секцию трогать нельзя.
Для написания вируса этого конечно мало, но перевести Entry Point и др. действия вы сможете выполнить сами.
А вот и некоторые битовые флаги, характеризующие секцию.
Object Flags:
00000020h
Секция содержит программный код
00000040h
Секция содержит инициализированные данные
00000080h
Секция содержит неинициализированные данные
20000000h
Секция является исполняемой (см. флаг 00000020h)
40000000h
Секция только для чтения
80000000h
Секция может использоваться для записи и чтения
Рекомендую установить такие флаги:
00000020h
+
20000000h
+
80000000h
=
A0000020hПервые 2 уменьшат подозрения у эвристических анализаторов, т.к. точка входа, указывающая на секцию, не являющуюся кодовой, смотрится неестественно, а последний делает секцию доступной для записи.
В принципе, того что я вам здесь написал, уже достаточно для написания рабочего вируса, но...
...рано расслабляться, придется рассмотреть еще одну тему, итак, выравнивание.
Приложение 1. Выравнивание.
Хотя данные примеры будут работать и с не выровненными значениями, это не значит, что эту тему можно пропустить. Почему? Неизвестно как поведут себя более поздние версии Windows, и вы не без основания обвините меня в том, что ваши вирусы получили GPF или загрузчик не сможет запустить такой файл. Поэтому желательно выровнять те поля, описание которых этого требует. Так что наберитесь терпения и разберитесь с тем, что я вам здесь объясню. Это вам еще ни раз понадобится. Приведу некоторые поля из описания PE формата Hard'а Wisdom'а.
PE Header:
RVA
Size
Name
Description
38h
DWord
Object Align
Выравнивание программных секций, должно быть степенью 2 между 512 и 256М включительно, так же связано с системой памяти. При использовании других значений программа не загрузится.
3Ch
DWord
File Align
Фактор, используемый для выравнивания секций в программном файле. В байтовом значении указывает на границу, на которую секции дополняются 0 при размещении в файле. Большое значение приводит к нерациональному использованию дискового пространства, маленькое увеличивает компактность, но и снижает скорость загрузки. Должен быть степенью 2 в диапазоне от 512 до 64К включительно. Прочие значения вызовут ошибку загрузки файла. Я так думаю, что размер файла штука более важная.
50h
DWord
Image Size
Виртуальный размер в байтах всего загружаемого образа, вместе с заголовками, кратен Object Align.
Object Table:
RVA
Size
Name
Description
08h
DWord
Virtual Size
иртуальный размер секции, именно столько памяти будет отведено под секцию. Если Virtual Size превышает Physical Size, то разница заполняется нулями, так определяются секции неинициализированных данных.
0Ch
DWord
Section RVA
Размещение секции в памяти, виртуальный ее адрес относительно Image Base. Позиция каждой секции выровнена на границу Object Align (степень 2 от 512 до 256М включительно, по умолчанию 64К) и секции упакованы впритык друг к другу. Впрочем, можно это не соблюдать.
10h
DWord
Physical Size
Размер секции (ее инициализированной части) в файле, кратно полю File Align в заголовке PE Header, должно быть меньше или равно Virtual Size. Играя с этим полем можно добиться некоторых результатов ;-) Загрузчик, по идее, хлопает всю секцию в отведенное ОЗУ.
14h
DWord
Physical Offset
Физическое смещение относительно начала EXE файла, выровнено на границу File Align поля заголовка PE Header. Смещение используется загрузчиком как seek значение.
Ясно, зачем я их привел?
Первые два поля Object Align и File Align - это те значения, на которые нужно выравнивать остальные. В описании полей написано что куда. Я же объясню, как это сделать.Что же такое выравнивание...
Выравнивание, это округление выравниваемого значения в большую сторону до кратности с выравнивающим фактором. Два первых поля Object Align и File Align и есть выравнивающие факторы для соответствующих полей.(выравнивающий фактор.... этот термин я ввел в свои статьи для краткости, может быть он и не совсем правилен, но, я думаю, вы меня поняли)
При выравнивании можно воспользоваться такой формулой:
(x+(y-1))&(~(y-1)), где,
x-выравниваемое значение
y-выравнивающий факторУточнение: выравнивающий фактор должен быть степенью двойки, иначе формула не будет иметь смысла.
Т.к. содержимое полей Object Align и File Align по утверждению Microsoft являются степенями двойки, мы можем смело использовать данную формулу.Хмм, это на первый взгляд выглядит сложно, на практике все просто и ясно.
Код (Text):
Скомпилируйте и посмотрите в отладчике, меняйте значения. Все встанет на свои места.
В примере Example2-2.asm находится код, который расширяет последнюю секцию у тестового файла и записывает себя в полученное пространство. Выравниваются все значения, которые этого требуют.
Интересно, что линкер ваткома устанавливает виртуальные длины секций в 0, но загрузчику на это плевать и он работает с такими файлами. Для наглядности я выровнял все значения, которые, судя по описанию из PE формата, должны быть выровнены.
Поясню некоторые действия, которые встречаются в примере Example 2.2.asm При выравнивании виртуальной и физической длин секции, необходимо учесть несколько моментов, это не обязательно, но уменьшит подозрения у антивирусов и пользователей, которые любят копаться в файлах всевозможными PE Explorer’ами.
Уточняю, все нижеописанное, справедливо в тех случаях, когда соблюдается равенство Virtual Size = Physical Size для каждой секции. Например:
Имя секции
Virtual Size
Physical Size
CODE
200h
200h
DATA1
400h
400h
DATA2
1000h
1000h
DATA3
200h
200h
В таком случае, выравнивать физическую и виртуальную длины секции по разному не нужно. Тут могут быть 3 взаимоисключающих варианта:
-если Virtual Size и Physical Size во всех секциях кратны наименьшему (но не кратны наибольшему) из SectAlignment, FileAlignment, то измененные Virtual Size и Physical Size изменяющейся секции должны быть кратны наименьшему из SectAlignment, FileAlignment
-если Virtual Size и Physical Size во всех секциях кратны наибольшему (а значит и наименьшему) из SectAlignment, FileAlignment, то измененные Virtual Size и Physical Size изменяющейся секции должны быть кратны наибольшему из SectAlignment, FileAlignment
-если Virtual Size и Physical Size хотя бы в одной секции не кратны ни одному из значений SectAlignment, FileAlignment, то выравнивать длины измененной секции не нужно, просто добавьте к ним не выровненный размер вашего кода.И еще один немаловажный момент, загрузчик от Windows 2000 следит за следующим равенством для виртуально последней секции:
VirtualSize + VirtualAddress = Image Size
Т.е. вам нужно будет приравнять поле Image Size к сумме полей Virtual Size и Virtual Address для виртуально последней секции. Естественно, что эту операцию нужно проводить после всех вышеописанных манипуляций.
III. Добавление новой секции.
Вы уже должны иметь достаточно знаний, чтобы справиться с добавлением секции своими силами. Но могут возникнуть некоторые проблемы, на которых вы можете споткнуться, поэтому я все же опишу основные действия, которые вам потребуются, и приведу пример добавления последней секции к заражаемому файлу.
Для этой части статьи, как и для второй, я написал 2 исходника. Они оба являются рабочими, но из первого я постарался убрать все, без чего он останется работоспособным. Т.е. глядя на него, вам будет проще понять сам принцип внедрения вируса. Второй исходник является расширенной версией первого. Например, выравнивание в нем происходит по определенным правилам, суть которых я раскрыл во второй части, также, учтено наличие Bound импортов. Приступим…
Вот описание еще одного значения из PE Header, которое я не давал. Его мы уже использовали в предыдущих частях и, я думаю, вы уже поняли, зачем оно нужно и что из себя представляет.
PE Header:
RVA
Size
Name
Description
06h
DWord
Num of Objects
Количество элементов в Object Table
Это поле отвечает за количество элементов, содержащихся в Object Table. После добавления новой секции мы должны провести инкремент этого поля, т.е. увеличить его на единицу, если, конечно, вы добавляете одну секцию. В противном случае увеличивайте его на число, равное количеству добавляемых секций. С этим все понятно…
Сложность может возникнуть при добавлении нового элемента в Object Table, т.к. в некоторых файлах присутствуют Bound импорты. В первой части этой статьи я уже говорил, что они находятся после Object Table, следовательно, при добавлении нового элемента мы можем их просто затереть.
Приложение 2 объясняет, что представляют собой Bound импорты, поэтому прежде чем читать дальше, настоятельно рекомендую заглянуть туда.
Теперь давайте посмотрим на код. Прежде чем добавлять элемент в Object Table, мы должны убедится в отсутствии Bound импортов, а если они присутствуют, то передвинуть их. Нижеприведенный код это и делает.
Код (Text):
Суть такова, если в файле имеются Bound импорты, то мы просто передвинем их вперед по коду на 40 байт, вследствие чего освободится место для нового элемента, который мы добавим. Тут нужно будет не забыть проверить, не «залезут» ли Bound импорты на первую секцию файла при их переносе.
С форматом элемента из Object Table, вы уже должны быть знакомы, для кого это новость, читайте описание формата PE файлов, т.к. во второй части статьи я это уже рассматривал.
Для заполнения полей VirtualSize и PhysicalSize возьмите размер вашего вируса, выровненный на соответствующие поля (Example3-1.asm), в Example3-2.asm выравнивание происходит по правилам, которые были оговорены в приложении 1.
При заполнении полей Section RVA и PhysicalOffset, важно помнить, что эти поля должны быть выровнены всегда!!!
Считаются они так:
SectionRVA(новой сек.) = SectionRVA(последней сек.) + VirtualSize(последней сек.)
PhysicalOffset(новой сек.) = PhysicalOffset(последней сек.) + PhysicalSize(последней сек.)В том случае, если, в соответствии с правилами выравнивания, длины секции вы оставили не выровнеными, не забудьте выровнять Section RVA и Physical Offset новой секции после расчетов. Чтобы не утруждать себя излишними проверками, выравнивайте их в любом случае.
После того как элемент заполнен, в том числе и поле характеристик секции, можете приступать к копированию кода вируса в новую секцию. EDI должен указывать на новый элемент в Object Table.
Код (Text):
Осталось пропатчить поле Image Size в PE Header. EDI указывает на новый элемент, а eax на PE Header.
Код (Text):
Приложение 2. Bound-импорты.
Впринципе, для успешного заражения файлов можно и не знать что такое Bound импорты и зачем они нужны. Но для полноты картины, а так же чтобы предупредить вопросы наиболее любопытных исследователей я включил в свои статьи эту главу.
Для тех, кому лень разбираться с нижеописанным, просто учитывайте, что в некоторых файлах могут присутствовать Bound импорты и в ряде случаев вам необходимо будет учесть их наличие. В PE Header есть поля, которые заключают в себе всю нужную вам информацию о Bound импортах, о чем я уже говорил в первой части статьи.
PE Header:
RVA
Size
Name
Description
D0h
DWord
Bound Import RVA
RVA Bound импортов
D4h
DWord
Bound Import Size
Размер Bound импортов
Теперь настало время объяснить что же они из себя представляют и для чего нужны...
Для начала необходимо познакомится с таким понятием как биндинг. Биндинг, это пропатчивание адресов импорта на этапе линковки программы или после нее при помощи специальных утилит. Смысл этого заключается в том, чтобы облегчить работу загрузчика при запуске вашей программы.Есть два вида биндинга, old style binding и new style binding.
Bound импорты существуют только при new style, но для того чтобы почувствовать разницу мы рассмотрим оба случая.При old style дело обстоит так...
Адреса функций в каталоге импорта пропатчены заранее, и загрузчик при запуске файла смотрит на TimeDateStamp (время создания) в структуре IMAGE_IMPORT_DESCRIPTOR каталога импорта загружаемого файла и на TimeDateStamp той dll'ки из которой импортируются ф-ии. Если они не идентичны, то загрузчик перепатчит адреса таких импортов, т.к. такая dll'ка имеет другое время создания, в следствии чего адреса импортируемых функций могут отличаться. Поле TimeDateStamp требуемой dll так же может иметь значение 0, что происходит, если для данных функций не было биндинга. В таком случае загрузчик пропатчит все адреса импортируемых функций в IMAGE_IMPORT_DESCRIPTOR которых поле TimeDateStamp было равно 0. Если имела место коллизия, т.е. dll из которой наш файл импортирует функции загружена не по своей Image Base, то так же происходит репатч всех адресов импортируемых функций из этой dll.А как же быть, если dll экспортирует функцию код которой содержится в другой dll, т.е. при форварде? Ведь у "другой" dll неизвестно время ее создания и версия...
Во избежания всех связанных с этим печальных последствий, в каталоге импорта загружаемого файла в структуре IMAGE_IMPORT_DESCRIPTOR есть поле ForwarderChain, которое содержит индекс первого импортируемого форварда в массиве FirstThunk. Элементом с таким индексом в массиве FirstThunk является элемент содержащий индекс следующего импортируемого форварда в этом же массиве. И так по цепочке, пока не встретится элемент со значением -1, что означает - форвардов больше нет.
Логика загрузчика такова, если он встретил ForwarderChain не равное -1, то он пройдет по цепочке форвардов и перепатчит их адреса, т.е. форварды перепатчиваются всегда!Теперь мы подходим к самому важному, а именно, что же представляет из себя new style binding и для чего нужны Bound импорты...
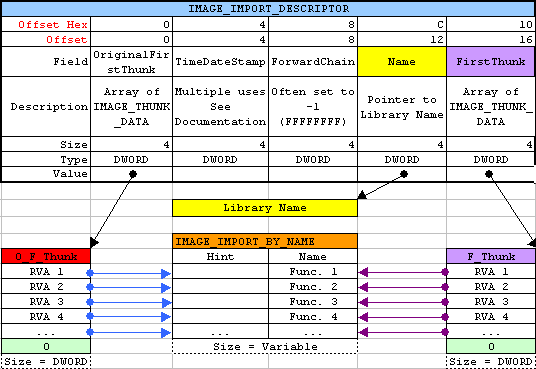
При new style, поля TimeDateStamp и ForwarderChain для dll'ок из которых происходит экспорт форвардов, всегда равны -1. И лоадер, обрабатывая такой IMAGE_IMPORT_DESCRIPTOR смотрит в директорию Bound импортов (IMAGE_DIRECTORY_ENTRY_BOUND_IMPORT), в которой содержатся информация о том сколько функций в каждой dll являются форвардами и TimeDateStamp всех модулей из которых происходят форварды, опять же, для каждой dll. В общем директория Bound импортов, призвана облегчить жизнь загрузчику. В принципе все происходит как и с обычными импортируемыми функциями, т.к. TimeDateStamp известен для каждого форварда и при равенстве времени создания dll, загрузчик не будет перепатчивать адреса импортируемых форвардов, что экономит время. Ниже приведена схема IMAGE_IMPORT_DESCRIPTOR, взятая из журнала Codebreaker's
Я постарался объяснить саму суть, без всевозможных нюансов, чтобы было понятно, зачем нужны Bound импорты и когда они присутствуют. Для тех кому хочется разобраться с этим подробнее, читайте Мэта Питрека и статью "Об упаковщиках в последний раз", которую можно взять с www.wasm.ru
Conclusion.
Вот и все, надеюсь, я довольно доступно объяснил простейшие методы внедрения кода в файлы формата PE EXE. Если остались вопросы или вы хотите услышать о других технологиях заражения, пишите мне на sars@ukrtop.com, PGP ключ я прилагаю в архиве с исходниками. Главное, уясните себе, что цель вирмейкинга заключается, прежде всего, в исследовании операционных систем и их уязвимостей, а не в том, чтобы напакостить соседу или людям которые этого не заслуживают. Поэтому, если вы больны на голову и у вас извращенные понятия, я за вас не в ответе.
© Sars / HI-TECH
Основные методы заражения PE EXE
Дата публикации 16 ноя 2004