Об упаковщиках в последний раз: Часть первая - теоретическая — Архив WASM.RU
Сложное – то, что делается мгновенно,
невозможное – то, что требует лишь
немногим большего времениРецензент:
Dr.Golova/UINC.RUГлавный корректор:
Edmond/HI-TECH
1. Лирическое отступление
2. Основные концепции2.1 RVA/VA и иже с ними
2.2 О секциях PE-файла
2.3 Директория импорта
2.4 Директория ресурсов
2.5 Директория перемещаемых элементов
2.6 NTDLL.DLL – Windows Loader3. 64-bit PE-files
4. Страшное слово XML
5. Благодарности1. Лирическое отступление
Решено было разбить эту статью на две-три части. Первая часть собственно теоретическая. Она дает абсолютно необходимый минимум теории, который позволит успешно распаковывать файлы. В статье также описывается формат XML, который затем переводится в CSS-HTML при помощи XSLT-процессора. Таким образом, наряду со знанием структуры PE-файла вы, по прочтении статьи, будете иметь самые базовые представления о XML/CSS/XSLT, Perl/Java и других страшных технологиях. Мы достаточно неплохо осознем, что тема уже достаточно замусолена, поэтому нудного пересказа PE-документации здесь не будет. Скорее, вам стоит воспринимать эту статью как некий коллектор, попытку обобщения и анализа всей доступной информации о пакерах, PE-файлах, антиотладке и т.п. А поскольку есть возможность перевода статей с испанского и французского языков (помимо стандартного английского), то должно получится что-то неплохое. Вторая часть будет чисто практической. Мы рассмотрим UPX, Aspack, Asprotect, Crunch, Armadillo и вскользь упомянем о других, менее популярных пакерах. Все опыты, приведенные в первой части проводились на calc.exe – стандартном калькуляторе из поставки Windows 2000. Вторая часть тоже будет проходить вместе с calc.exe. Реальные случаи будете рассматривать сами. Последнее, но немаловажное замечание – ВСЕ, что здесь обсуждается, валидно ТОЛЬКО для Windows 2k/XP/2003 (последняя – с натяжкой!). 9x НЕ рассматривается как анахронизм. Замечание важно, т.к. 9x и NT по-разному трактуют оперативную память, загружают библиотеки, работают с процессами, обрабатывают исключения и т.п.
Для того чтобы понимать, что здесь написано, введем пару допущений. Допущение номер раз: вы знаете ассемблер; №2: вы знаете, что такое исполняемый файл, т.е. файл загружается с диска в оперативную память с помощью механизмов ОС, при этом ОС определенным образом может при загрузке корректировать информацию внутри файла, если это необходимо; №3: вы слышали о языке программирования Perl; №4 – вы имеете очень приличное представление о базовых типах языка С – структурах, массивах и т.п., последнее – пятое – вы имеете хоть и очень смутное, но все же какое-то представление о том, что такое PE-формат исполняемого файла.
2. Основные концепции
Теперь, наконец, давайте рассмотрим формат PE-файла. Скажем сразу, что в наши намерения не входило давать здесь пересказ технической документации MS. Файл со спецификациями PE/COFF при-ложен, на wheaty.net есть статьи Питрека на эту тему. Полагаем, в русской части Интернета сравнительно просто найти саму книгу Питрека. Из русской литературы можно предложить Румянцева, где неплохо описаны поля, и даже есть исходники, хотя их качество нам не нравится, и статью о загрузчике PE-файлов на RSDN.ru – там все расписано очень неплохо, есть и исходники, но они на Delphi, а этот язык мы не знаем и не любим. Однако алгоритм, по справедливому замечанию автора, везде одинаков.
Да, чуть не забыли. Для хорошо знающих английский, есть абсолютно великолепная вещь, совершенно свободно распространяемая - http://www.iecc.com/linker/ - слейте ее целиком, и обязательно прочтите, просто изумительно! Книга будет продублирована и на WASM.RU, ибо вполне стоит того! Практическим примером к этой книге может служить техническая документация с сайта http://www.cs.virginia.edu/~lcc-win32/ - Якоб Навия очень неплохо расписывает многие тонкости по созданию компилятора и линкера. Еще дополнительно прилагается англоязычное описание PE-формата (версия 1.7) от Lumnificer, где подробно расписываются все поля, и даже объясняется, как создавать PE-файл ручками, т.е. расписывается работа примитивного линкера!
Так же, посоветуем изучить исходный код программы Wine – эмулятора Windows для Linux. Wine умеет загружать pe-файлы под Linux, причем код pe_image.c написан очень развернуто. А там еще мно-о-го примеров есть… Сайт - http://www.winehq.com.
Теперь очень быстренько пробежимся по списку литературы, описывающего работу NTDLL.dll – Windows loader'а.
Нашими маяками в этом бушующем море станут статьи Питрека.
А также, основанная на этом статья Russell Osterlund с сайта http://www.smidgeonsoft.com, название статьи – "Windows 2000 Loader: What Happens Inside Windows 2000: Solving the Mysteries of the Loader" – лежит на MSDN. Лучше пока еще ничего не написано. Примеры для статьи скачивайте только с MS, родной сайт лучше не трогать. Причем после слива можно смело удалить все dsp/dsw/ncb/suo/sln файлы, оставив только vcproj. Причина в том, что все файлы проектов повреждены, во всяком случае, VS.NET 2003 их открыть не смогла. Другое дело vcproj, который, по сути, является простым xml-файлом. Подредактируйте их немного (неправильно прописаны пути Output Directory и т.п.), и держите в уме, что проект Forwarder требует lib-файл проекта Forwarded, поэтому второй должен собираться раньше.Во всей остальной части статьи мы будем жестко придерживаться терминов, принятых Microsoft. Все определения структур взяты из winnt.h. Эта мера кажется очень разумной, т.к. на данный момент существует дикая неразбериха в терминах - существует целая куча слов, для которых нет четких определений, например, секция импорта, таблица импорта, IAT и т.п. Каждый писатель под этими словами понимает что-то свое, в результате чего имеем полный беспредел.
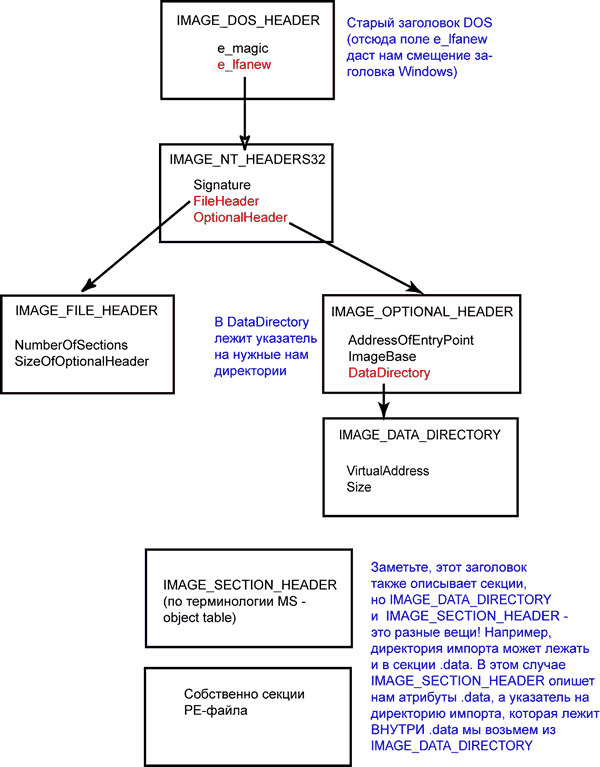
Теперь взгляните на рисунок ниже:
Рис. 1. Мы предполагаем, что вы оторветесь от чтения этой статьи и проведете несколько минут с этим рисунком и официальной документацией от MS, держа в уме, что PE файл, по сути, просто совокупность секций, которые описываются в заголовке.
Единственное что, стоит объяснить несколько нюансов.2.1 RVA/VA и иже с ними
RVA переводится как Relative Virtual Address - относительный виртуальный адрес. Его относительность заключается в том, что он отсчитывается от адреса загрузки, который может быть, а может и не быть, равен ImageBase.
Обязательно учтите, что RVA имеет РАЗНЫЙ смысл для бинарных файлов (exe, dll, sys) и объектных файлов (obj, lib). Вторые мы здесь не рассматриваем, а для первых – файл загружается в память и RVA какого-либо элемента вычисляется так:RVA = VA – адрес загрузки,где VA (Virtual Address) – виртуальный адрес элемента в памяти, а адрес загрузки берется из поля Op-tionalHeader.ImageBase, в том случае, если он равен ImageBase, либо вычисляется лоадером.
Обратите внимание на то, что элементарные просмотрщики файла, например, QVIEW/WinHEX и т.п. отображают абсолютные offset-ы, HIEW способен переключаться (Alt+F1) между показом VA и внутрифайловых смещений (local/global mode), а IDA вообще частично эмулирует работу ntdll.dll – Windows-loader'a, поэтому показывает только VA (если вы не укажете иное, например, загрузив файл как "binary").
Давайте рассмотрим пример для практического усвоения материала. Точка входа calc.exe (также часто называемая EP – entry point) выглядит так:.01012420: 55 8B ;VAА в виде абсолютных внутрифайловых смещений – вот так:
00011A20: 55 8B ;обратите внимание на отсутствие точки! ;HIEW требует точку, если хотите VA!Давайте попытаемся разобраться, какой же механизм пересчета VA во внутрифайловые смещения.
Алгоритм примерно выглядит так:
1) По VA рассчитать RVA
VA = RVA + ImageBase2) Для RVA найти секцию, в которой мы находимся (о секциях мы поговорим чуть ниже).
3) Пересчитать RVA во внутрифайловый offset по формуле:
offset = RVA - IMAGE_SECTION_HEADER.VirtualAddress + + IMAGE_SECTION_HEADER.PointerToRawDataТеперь давайте посчитаем ручками. В качестве примера возьмем адрес точки входа calc.exe - 0x01012420.
Сразу смотрим в HIEW на значение ImageBase -
VA = RVA + ImageBase; 01012420 = RVA + 1000000; RVA = 12420; //что можно сразу увидеть из OptionalHeader.EntryPointТеперь определяемся, где же у нас лежит этот RVA. Ага, RVA лежит в секции .text. Обратите вни-мание на то, что лежит он ближе к концу секции:
Number Name VirtSize RVA PhysSize Offset Flag 1 .text 000124EE 00001000 00012600 00000600 60000020 Теперь VA во внутрифайловое смещение:
offset = 12420 - 1000 + 600 = 11A20;Заметим, что процесс этот уже давным-давно автоматизирован. Есть такие утилиты как LordPE и PE Tools, а в них есть такая вещь как FLC (File Location Calculator), который по данному VA отобразит RVA и внутрифайловый offset.
Имея на руках некоторые API-функции - GetModuleHandle, ImageRvaToVa и ImageRvaToSection, несложно написать программу, которая быстренько переведет любой VA во внутрифайловый оффсет. Например, аналог функции от MS ImageRvaToSection может выглядеть где-то так:/*********************** * Return value: Возвращается структура IMAGE_SECTION_HEADER, для данного RVA * Parameters: Первый – это структура IMAGE_FILE_HEADER * Parameters: Второй – это RVA для которого нужно найти секцию ************************/ PIMAGE_SECTION_HEADER RvaToSection(PIMAGE_FILE_HEADER pFH, DWORD dwRVA) { UINT i; IMAGE_SECTION_HEADER *pSH; pSH = (PIMAGE_SECTION_HEADER)((DWORD)(pFH + 1) + pFH->SizeOfOptionalHeader); for (i = 0; i < pFH->NumberOfSections; i++) { if (dwRVA >= pSH->VirtualAddress && dwRVA < pSH->VirtualAddress + pSH->Misc.VirtualSize) return pSH; ++pSH; } return NULL; }Примеры функций RtlImageRvaToVa /RtlImageRvaToSection /RtlImageDirectoryEntryToData есть в файле loader.c из wine.
Например, есть у вас есть dll, загруженная по адресу, отличному от ImageBase. Вы нашли защиту в Soft-Ice, и хотите пропатчить это место HIEW'вом - тут-то и пригодится умение.
2.2 О секциях PE-файла
PE-файлы были спроектированы для работы в ОС со страничной адресацией памяти. Известно, что Windows делит память на страницы различного размера, поэтому и PE-файл разбит на секции. Это очень важно понимать, поскольку секции PE-файла в памяти и на диске - это вовсе не одно и то же! В том случае, если сами данные в секции имеют общий объем менее размера кластера - секция на диске выравнивается (т.е., дополняется нулями, int3 - CCh или nop – 90h) под размер кластера (не путать с сек-тором – кластеры состоят из многих секторов диска!), который обычно равен 512 байтам (или другое значение – поле OptionalHeader.FileAlignment).
Когда файл загружается, то секция попадает в страницу памяти большего размера – 4 кб (или дру-гое значение - OptionalHeader.SectionAlignment), и выравнивается вновь, если это необходимо, уже только нулями. Обратите вниманиме, мы говорим "секция" – т.е., секция .text, CODE, .data, DATA, .aspack или что-либо еще. Каждая секция будет проецироваться на одну или несколько страниц памяти.
Не путайте понятие "Секция" (section) и "Директория" (directory). Директории (импорта, экспорта, ресурсов, исключений или чего-то еще) находятся ВНУТРИ секций. Заметьте, секция определяет разбиение PE-файла на части, но секции глубоко все равно, какой тип данных будет находится внутри нее. Для того, чтобы охарактеризовать тип, у нас есть директории! Директории характеризуют данные, содержащиеся в PE, по их типу и функциональности. Таким образом, можно говорить, что секция является физическим разбиением PE файла на состовляющие, а директория - логическим.
Иногда размер секции может занимать много кластеров, и отображаться Windows на несколько страниц памяти. Общее количество секций должно в точности соответствовать полю FileHeader.NumberOfSections. Теоретически, с этим шутить не стоит, так как шаг в сторону – стреляю. Такой файл не будет опознан ntdll.dll, поэтому на поле NumberOfSections можно смело(?) опираться. Однако и здесь нам уже радость испортили! Некоторые крипторы, например, telock, заменяют это значение в ПАМЯТИ, например, на 0xFFA4. Угадайте, что случится, когда вы попытаетесь запустить дамп с такого файла? А что будет, если утилита, просматривающая содержимое полей секций в цикле, будет ориентироваться на такую переменную как на счетчик цикла, нечто вроде такого:
for (i=0; i<= FileHeader.NumberOfSections; i++) //где FileHeader.NumberOfSections == 0xFFA4 { //Здесь обрабатываем содержимое секции //А теперь представим, что секции закончились. О-о-о-о-й! //да, попробуйте такой файл посмотреть HIEW. Забавная реакция! }Как вариант, можно использовать значение NumberOfSections с диска. Другую альтернативу мы рассмотрим, после того как ознакомимся со структурой секции изнутри.
LordPE, HIEW на этот трюк покупаются! Все версии IDA - тоже! PE Tools – нет! Прекрасная защита от сброса дампа на диск (имеется в виду, дамп сбросить можно, а вот заставить его заработать потом.... тоже можно, но чуть посложнее)! Хотя, с другой стороны, такой файл не будет загружен самой Windows. Цитирую Евгения Сусликова: "не должно быть хиеву умнее виндов". Что ж, вполне справедливо.
Для каждой секции в заголовке PE-файла указан ее размер на диске и в памяти. Структура выглядит так:#define IMAGE_SIZEOF_SHORT_NAME 8 typedef struct _IMAGE_SECTION_HEADER { //имя не более 8 символов BYTE Name[IMAGE_SIZEOF_SHORT_NAME]; union { DWORD PhysicalAddress; DWORD VirtualSize; //помеченные красным значения характеризуют секцию в памяти //VirtualSize – общий размер секции в памяти. //если это число БОЛЬШЕ размера секции на диске // – секция дополняется нулями } Misc; DWORD VirtualAddress; //RVA первого байта секции в памяти //синий шрифт – данные о секции на диске DWORD SizeOfRawData; //Размер ИНИЦИАЛИЗИРОВАННЫХ данных на диске //Ой, какое интересное поле! Поговорим о нем чуть ниже. //Вкупе с VirtualSize им часто пользуются протекторы DWORD PointerToRawData; //очень полезное поле – offset от начала файла до первого байта секции DWORD Characteristics; //характеристики секции – это поле тоже очень любят менять, // поговорим ниже и о нем } IMAGE_SECTION_HEADER, *PIMAGE_SECTION_HEADER;Особый интерес в этой структуре вызывают два поля – VirtualAddress и SizeOfRawData. Все остальные тоже очень интересны, но эти два широко используются протекторами для сокрытия от наших глаз того, что должно быть скрыто. К примеру, вам, вероятно, часто доводилось видеть нечто вроде такого в IDA:
.data1:005B6FFD db 0 ; .data1:005B6FFE db 0 ; .data1:005B6FFF db 0 ; .data1:005B7000 db ? ; .data1:005B7001 db ? ; .data1:005B7002 db ? ; .data1:005B7003 db ? ;в то время как самый обычный hex-редактор выдавал вполне осмысленные цифры. Проблема и ее решение достаточно просты. Обратите пристальное внимание на поля VirtualSize и SizeOfRawData той секции, где есть такой подарочек. Значение SizeOfRawData должно быть меньше значения поля VirtualSize:
Number Name VirtSize RVA PhysSize Offset Flag 1 .text 00195C5C 00001000 00000000 00000000 60000020 2 .data 00008DD4 00197000 00000000 00000000 C0000040 3 .text1 00010000 001A0000 0000F000 00001000 60000020 4 .data1 00020000 001B0000 00007000 00010000 C0000040 5 .pdata 000B0000 001D0000 000B0000 00017000 C0000040 6 .rsrc 00001000 00280000 00001000 000C7000 40000040 Именно поэтому и появляются знаки вопроса – IDA ориентируется только на raw-байты (хотя, в случае секции кода с этим можно поспорить). Чтобы исправить положение, надо просто приравнять значение SizeOfRawData значению VirtualSize. И, вуаля:
.data1:005B7000 aPdata000_0 db 'PDATA000' .data1:005B7008 db 2 ; .data1:005B7009 db 1 ;Заметим также, что ни VirtualSize, ни SizeOfRawData различных секций перекрываться не могут. Таким образом подправленный файл просто не будет загружен.
Возможен и еще, например, такого рода трюк. Положим, есть файл, у которого ручками создана несуществующая директория отладки (Debug Directory):#define IMAGE_DIRECTORY_ENTRY_DEBUG 6Структура директории выглядит так:
typedef struct _IMAGE_DEBUG_DIRECTORY { DWORD Characteristics; DWORD TimeDateStamp; WORD MajorVersion; WORD MinorVersion; DWORD Type; DWORD SizeOfData; DWORD AddressOfRawData; DWORD PointerToRawData; } IMAGE_DEBUG_DIRECTORY, *PIMAGE_DEBUG_DIRECTORY;Положим, мы задали заведомо огромные значения полей SizeOfData, AddressOfRawData и PointerToRawData. Лоадера эти поля абсолютно не интересуют (ему важна лишь валидность параметров в IMAGE_DATA_DIRECTORY). Прямо сказано, что эти поля касаются только отладчика (или дизассемблера). Так вот, IDA на таком файле (до версии 4.3 включительно) слетит наглухо! Такого рода трюк (© Dr. Golova) был применен в программе, которую рассматривал Sten в своей статье – "Исследование подаруночка" на reversing.net, если кто помнит.
Популярны также трюки с директориями импорта-экспорта. Некоторые поля (OriginalFirstThunk, например) забивают 0xFFFFFFFF или чем-нибудь не менее гадким - RVA OriginalFirstThunk должно, согласно действиям лоадера (Win2k SP4), укладываться в диапазон
cmp ecx, [eax+IMAGE_NT_HEADERS.OptionalHeader.SizeOfHeaders] jb loc_77F9373F ;если меньше SizeOfHeaders cmp ecx, [eax+IMAGE_NT_HEADERS.OptionalHeader.SizeOfImage] jnb loc_77F9373F ;и больше либо равно SizeOfImage
если это не так – файл загружен не будет. В этих случаях IDA говорит "Can't find a translation for virtual address…", и … раньше слетала, а теперь продолжает работу. HIEW в своей работе на winnt.h не опирается вообще, он был создан раньше. Валидность адресов директории импорта/экспорта проверяется валидностью VA. Мы поговорим о подобных приемах немного позднее.Флаги секции – тоже вещь небезынтересная! Здесь мы не будем углубляться в детали. Скажем лишь, что флаги секции могут преобразовываться лоадером в атрибуты страниц и сегментов, биты CR-регистров и т.д. Это достаточно сложная тема, требующая неплохого понимания принципов работы защищенного режима. Мы бы порекомендовали Рендалла Хайда "Art of Assembly" и Михаила Гука. Заодно можно почитать Фроловых, а также ознакомится со статьями Broken Sword на WASM.RU. После этого можно смело утверждать, что вы будете является одним из очень твердых специалистов по защищенному режиму процессоров х86
. Такое знание не будет бесполезным. Например, понимание принципов защиты страниц виртуальной памяти помогает практически однозначно идентифицировать Aspack. Сбросьте флаг разрешения записи у секции кода в программе, предположительно запакованной Aspack, и взгляните на результаты. Почему такое происходит – мы поясним во второй части. Обязательно обратите внимание - это поле НИКОГДА не должно быть равным нулю. Как это можно использовать - см. ниже.
Сейчас уместным было бы посоветовать на какое-то время отвлечься от статьи, и попробовать поэкспериментировать с секциями файла. Да, мы сделаем это немного позднее, во второй и третьей частях, когда будем чистить файл от мусора, оставленного крипторами, однако, то, что сделано собственными руками, едва ли когда-нибудь забудется. Например, попробуйте поставить поле VirtualSize какой-нибудь секции в ноль (как, например, это делает линкер от Watcom). Также учтите, что количество страниц в памяти не обязательно будет соответствовать количеству секций в PE-файле. Во-первых, размер, во-вторых – сама Windows просто не загрузит страницу памяти до тех пор, пока она не нужна. Только если страница нужна, тогда она будет подгружена.
Еще нюанс. Все упаковщики, пакеры и крипторы очень нежно относятся к секции .rsrc. Секция кода, директрия импорта – все это безжалостно калечится, однако секцию ресурсов трогать боятся. При-чина проста. В исходном коде UPX можно найти следующие комментарии:
// after some windoze debugging I found that the name of the sections // DOES matter :( .rsrc is used by oleaut32.dll (TYPELIBS) // and because of this lame dll, the resource stuff must be the // first in the 3rd section - the author of this dll seems to be // too idiot to use the data directories... M$ suxx 4 ever! // ... even worse: exploder.exe in NiceTry also depends on this to // locate version infoИ действительно. В файле oleaut32.dll можно найти следующие строки, сохранившиеся там со времен 95-го по 2k и выше:
.77A078C7: 7825 js .077A078EE -----v (2) .77A078C9: 8D4580 lea eax,[ebp][-80] .77A078CC: 687CB7A377 push 077A3B77C -----v (3) .77A078D1: 50 push eax .77A078D2: FF15F8229B77 call lstrcmpiA ;KERNEL32.dll .77A3B770: 44 00 49 00-52 00 00 00-2A 00 00 00-2E 72 73 72 D I R * .rsr .77A3B780: 63 00 00 00-00 00 00 00-74 79 70 65-6C 69 62 00 c typelibИ из-за откровенно неумного, недальновидного, …, не будем перечислять, поведения программиста, кракеры получили большой подарок, а авторы пакеров – подарок поменьше. Спасибо, Microsoft! И абсолютно без всякой иронии! Так что, если автор хочет, чтобы его файл имел красивую иконку, то он должен предоставить ресурсы файла в наглядном виде. Конечно, не все так просто, секция ресурсов то-же безжалостно калечится, однако, вероятность того, что название секции будет сохранено наряду с иконкой, очень велика. Что до остального.… Разберемся с этим чуточку попозже.
Сказанное выше справедливо для всех приложений, имеющих ресурсы (очевидно, часто, но не всегда, консольные приложения к таковым не относятся).
В заключение, рассмотрим алгоритм подсчета количества секций PE-файла. Как уже упоминалось, поле FileHeader.NumberOfSections не может служить достаточно надежным проводником. Тогда что? Пока мы используем этот алгоритм (к слову, тоже ненадежный), но, возможно, после выхода статьи, он уже не будет работать в силу вполне определенных причин. Тогда нам с вами останется последний верный и надежный способ – считать значение из файла диске. Многие утилиты это позволяют. Итак, производим подсчет секций, и смотрим на поля PointerToRelocations, PointerToLinenumbers, NumberOfRelocations, NumberOfLinenumbers. Если все эти поля равны нулю, а поле Characteristics - НЕТ, значит - это секция.
Алгоритм прост:
/*********************** * Return value: настоящее значение NumberOfSections * Parameters: pMem - возвращаемое значение * от CreateFileMapping, либо от GetModuleHandle ************************/ WORD GetRealNumberOfSections(PVOID pMem) { PIMAGE_DOS_HEADER pDosh; PIMAGE_NT_HEADERS pNTh; PIMAGE_SECTION_HEADER pSh; WORD iRealNumOfSect = 0; // Устанавливаем SEH __try { // Считывает IMAGE_DOS_HEADER pDosh = (PIMAGE_DOS_HEADER)pMem; // Считываем IMAGE_NT_HEADERS pNTh = (PIMAGE_NT_HEADERS)((DWORD)pDosh + pDosh->e_lfanew); // Получаем указатель на первую секцию pSh = IMAGE_FIRST_SECTION32(pNTh); // Считываем секции по очереди for(word i = 0; i < (pNTh->FileHeader.NumberOfSections); i++) { if(!pSh->PointerToRelocations && !pSh->PointerToLinenumbers && !pSh->NumberOfRelocations && !pSh->NumberOfLinenumbers && pSh->Characteristics) // Увеличиваем счётчик секций iRealNumOfSect++; else return iRealNumOfSect; ++pSh; // Переходим к следующей секции } return iRealNumOfSect; } __except(EXCEPTION_EXECUTE_HANDLER) { // Ошибка “Access Violation!” return 0; } }Уже упоминалось, что линкер Watcom устанавливает значение поля VirtualSize в нуль. Тогда возникает вопрос - откуда брать VirualSize? Рекомендуется использовать значение поля SizeOfRawData, выровненное по SectionAlignment. Ниже указан макрос на C++ для выравнивания секции по SectionAlignment:
#define RALIGN(dwToAlign, dwAlignOn) ((dwToAlign % dwAlignOn == 0) ? dwToAlign : dwToAlign - (dwToAlign % dwAlignOn) + dwAlignOn)Используется так: VirtualSize = RALIGN(VirtualSize, SectionAlignment);
Eще немного об ImageBase. Понятия «директория кода» не существует. Есть только секция кода, которая может называться, как душе угодно. Начало секции вычисляется из IMAGE_OPTIONAL_HEADER.BaseOfCode. В случае, если значение поля AddressOfEntryPoint не укладывается в диапазон,
BaseOfCode<=AddressOfEntryPoint<=SizeOfCode
то это внимательному человеку может говорить о многом. Во-первых, файл, вероятно, запакован (почему так – см. часть вторую). Во-вторых, теперь вам придется сушить мозги с его распаковкой. Некоторые утилиты, например, OllyDbg, это дело подмечают, о чем вежливо предупреждают. Мало ли что?Теперь перейдем к директории импорта.
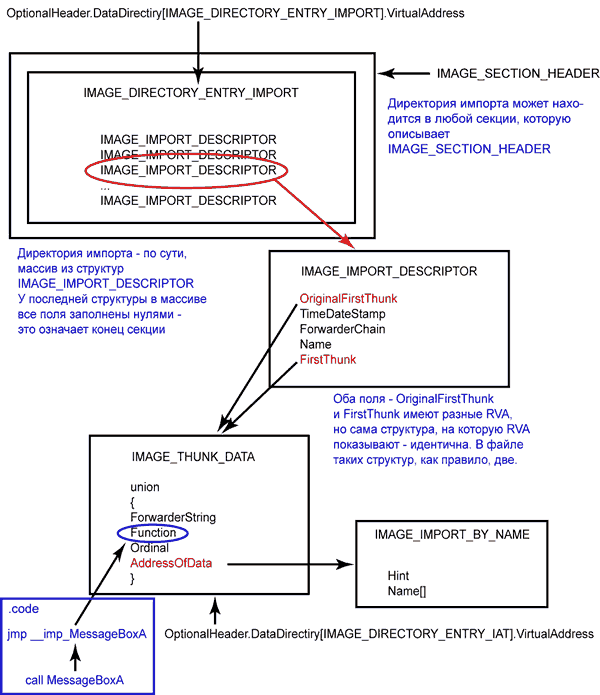
2.3 Директория импорта
Рис. 2. Для закрепления увиденного материала, опять таки, рекомендуется немного оторваться от чтения, и что-то поклацать. Все пояснения полей есть и в англо- и в русскоязычной документации.
Однако перед тем как перейти к прикладным аспектам, давайте немного разберемся с путаницей в терминологии. Прежде всего, массив из структур IMAGE_IMPORT_DESCRIPTOR иначе как директорией импорта называть некорректно. Структура эта содержит ряд полей, среди которых есть OriginalFirstThunk и FirstThunk. Очень важно понимать состояние структур, на которые эти поля показывают. Структуры называются IMAGE_THUNK_DATA – их две!
OriginalFirstThunk ? IMAGE_THUNK_DATA №1 /*обратите внимение, этой структуры может не быть, точнее, адреса будут заполнены нулями – это можно считать багом борландовского линкера. MS утилита bind.exe отказывается обрабатывать такой файл, почему так – см. ниже*/ FirstThunk ? IMAGE_THUNK_DATA №2До загрузки образа в память OriginalFirstThunk и FirstThunk содержат RVA (которые, естественно, тоже различаются) на эти структуры, являющиеся ни чем иным, как таблицами адресов импорта (IAT – import address table). Но и здесь уже тоже наизобретали велосипедов! IMAGE_THUNK_DATA на которую указывает OriginalFirstThunk ntdll.dll при загрузке в нормальных условиях не обрабатывается (хотя внутренняя функция ntdll.dll LdrpSnapIAT может читать и оттуда, см. ниже), а адреса в структуре, на которую указывает FirstThunk действительно меняются (патчатся лоадером), поэтому OriginalFirstThunk называют еще import lookup table (import name table), а FirstThunk – вот это уже настоящая IAT, для которой есть свой #define:
#define IMAGE_DIRECTORY_ENTRY_IAT 12Была когда-то и СЕКЦИЯ импорта, звали .idata, но сейчас она, пожалуй, издохла. Во всяком случае, сейчас этот зверь – редкий. Разве что линкер специально попросите...
Забавно, что даже LordPE, написанный действительно талантливым программистом, и тот не избежал этого бага. Поглядите потом, что вытворяет! Кнопочка – Directories, а директорию импорта называет IAT, а offset вообще обалденный выдает! PETools зато отображает корректно и термины корректные.
Теперь рассмотрим саму структуру и манипуляции с полями. Итак:
typedef struct _IMAGE_IMPORT_DESCRIPTOR { union { // 0 for terminating null import descriptor DWORD Characteristics; // RVA to original unbound IAT (PIMAGE_THUNK_DATA) DWORD OriginalFirstThunk; }; DWORD TimeDateStamp; // 0 if not bound, // -1 if bound, and real date\time stamp // in IMAGE_DIRECTORY_ENTRY_BOUND_IMPORT (new BIND) // O.W. date/time stamp of DLL bound to (Old BIND) DWORD ForwarderChain;// -1 if no forwarders, //положительное число в противном случае // RVA на имя dll DWORD Name; // RVA to IAT (if bound this IAT has actual addresses) DWORD FirstThunk; } IMAGE_IMPORT_DESCRIPTOR;Перед тем, как начинать разбирать структуру, очень важно четко представлять, что в последнее время развелось много всяких наворотов на бедную IAT.
NTDLL.dll (функция LdrpWalkImportDescriptor) может читать IAT из:
1) OptionalHeader.DataDirectory[IMAGE_DIRECTORY_ENTRY_IMPORT] - из IMAGE_IMPORT_DESCRIPTOR.OriginalFirstThunk, если удовлетворяются определенные условия. 2) OptionalHeader.DataDirectory[IMAGE_DIRECTORY_ENTRY_IAT] – т.е., из IMAGE_IMPORT_DESCRIPTOR.FirstThunk - это стандарт 3) OptionalHeader.DataDirectory[IMAGE_DIRECTORY_ENTRY_BOUND_IMPORT] - все файлы Windows имеют такую привязкуЕсть и 4-й #define:
#define IMAGE_DIRECTORY_ENTRY_DELAY_IMPORT 13 // Несмотря на #define в winnt.h определений полей структуры вы там не найдете. // Структура определена в delayimp.h в директории VC. // Малоизвестен тот факт, что линкер // от MS умеет также ассемблировать код! // Так вот, именно это здесь и используется. // В исполняемый файл просто-напросто запихиваются // дополнительные клочки кода.NTDLL.dll это не патчит, т.к. здесь уже используется совсем другой механизм. Фактически, это аналог LoadLibrary/GetProcAddress в одной упаковке. Более подробно - как всегда, Мэтт Питрек.
Здесь тоже понаворочено более, чем достаточно. Внутри Delay Load Directory Table есть стандартная таблица импорта, может выполняться привязка, т.е. возникать Bound Delay Import Table, есть Unload Delay Import Table и т.п. Мало не покажется!
LordPE понимает, что такое директория отложенного импорта. PE Tools пока выдает только VirtualAddress и Size (т.е. стандартные описания директории), HIEW (включая 6.85) вообще не умеет работать с директориями, IDA, хм.., IDA знает все.
Теперь у лоадера есть выбор – из какого же поля, собственно читать? Сначала обрабатывается цепочка директорий. Функция LdrpWalkImportDescriptor обрабатывает ТОЛЬКО директорию привязанного импорта, если VirtualAddress директории IMAGE_DIRECTORY_ENTRY_BOUND_IMPORT не равен нулю, и временные пометки (TimeDateStamp), зашитые внутри модуля при его создании, соответствуют таковым в библиотеках, к которым этот модуль привязан (системные библиотеки Windows, dll приложения и т.п.).
В случае отсутствия IMAGE_DIRECTORY_ENTRY_BOUND_IMPORT (или невыполнения некоторых условий, например, загрузки экспортируемого модуля не по адресу ImageBase) читается уже стандартный IMAGE_IMPORT_DESCRIPTOR.
Так же уже не вполне ясна роль поля IMAGE_IMPORT_DESCRIPTOR.TimeDateStamp, которое может иметь три значения:
- 0 – стандартный IMAGE_DIRECTORY_ENTRY_IMPORT.
- ххххххххh – из IMAGE_IMPORT_DESCRIPTOR.FirstThunk, но с некоторыми оговорками, см. ниже.
- -1 – лоадер читает из IMAGE_DIRECTORY_ENTRY_BOUND_IMPORT. Как уже говорилось, в этом случае лоадеру совершенно безразлично (при соблюдении определенных условий), есть ли IMAGE_DIRECTORY_ENTRY_IMPORT вообще или нет! Если попытка чтения BOUND_IMPORT проваливается в силу, например, несовпадения TimeDateStamp у exe файла и dll, к которым он привязан, то тогда читается стандартная IMAGE_DIRECTORY_ENTRY_IMPORT, но как при этом обрабатывается –1 – неясно. Во всяком случае, в коде LdrpWalkImportDescriptor НЕТ сравнения TimeDateStamp с -1, поэтому можно предположить, что достаточно существования IMAGE_DIRECTORY_ENTRY_BOUND_IMPORT.
Теперь продолжим исследование. Начнем с поля Name. Это RVA на ASCIIZ-строку нужной библиотеки. Совершенно неоправданно на нее опираются во многих алгоритмах, где массив из структур IMAGE_IMPORT_DESCRIPTOR обрабатывается в цикле. С одной стороны да, если имя библиотеки не указано, то откуда изволите функцию импортировать, а с другой стороны – есть поле TimeDateStamp, которое может быть равно –1, точнее, есть директория BIAT (есть и такое название у директории привязанного импорта), и, если она присутствует, о старой директории импорта можно забыть! И можно вытворять, что душе угодно с массивом из IMAGE_IMPORT_DESCRIPTOR, лоадера это нисколько не волнует! Т.е. утилита, обрабатывающая такой файл, это дело должна учитывать, т.е. частично эмулировать работу лоадера. PE Tools это умеет. LordPE - тоже.
При TimeDateStamp == 0 мы имеем дело со старой доброй стандартной IAT. До загрузки OriginalFirstThunk и FirstThunk имеют одинаковую структуру (IMAGE_THUNK_DATA), которая физически продублирована в разных местах РЕ-файла. После загрузки FirstThunk содержит реальные адреса функций, OriginalFirstThunk остается такой же. Лоадер патчит адреса в FirstThunk, меняя атрибуты страницы на время выполнения этой операции.
При TimeDateStamp равном ххххххххh имеем интересный случай со «старой привязкой». Важно понимать, что в этом случае лоадер не делает ничего! Пара проверок на валидность и образ можно запускать! Добиться эффекта можно, запустив утилиту bind с ключом –o.
bind –o –u filename // без ключа -u изменения в образ записаны не будут, // если интересно, что // происходит - используйте ключ -v. В этом случае утилита просто // озвучит свои действия, но файл не изменитПоле OriginalFirstThunk не затрагивается, а поле FirstThunk содержит настоящие адреса API-функций. Т.е. IMAGE_IMPORT_BY_NAME смысла более не имеет, т.к. DWORD в IMAGE_THUNK_DATA теперь, по сути, представляет адрес API-функции в памяти, а не ссылку на IMAGE_IMPORT_BY_NAME.
Импорт может просто привязываться, а может и происходить так называемый “API forwarding”, что можно перевести как "перенаправление API". Это очень изящная штука, которая помогает MS скрывать разницу между OS. Классический пример с HeapAlloc. Определена в kernel32.dll, но в действительности КОДА ее там и близко нет! Вместо этого вызов сразу перенаправляется на ntdll.dll, где упирается в функцию RtlAllocateHeap! Т.е. где-то так:
calc.exe -> kernel32.dll -> ntdll.dll (call HeapAlloc) (немедленный форвард) (RtlAllocateHeap) (NTDLL.RtlAllocateHeap) Этого эффекта можно добиться, употребляя следующее выражение при компиляции dll:
#pragma comment(linker, "/export:HeapAlloc=NTDLL.RtlAllocateHeap")Аналогичного эффекта можно добиться и с помощью def-файла:
EXPORTS HeapAlloc=NTDLL.RtlAllocateHeapExe-файл, использующий dll c таким редиректом, должен загружать ее динамически – через LoadLibrary/GetProcAddress(“HeapAlloc”) - если импорт по имени, либо по ординалу с помощью макроса MAKEINTRESOURCE. Если хотите линковать статически - тоже нет проблем. Код dll:
#include <windows.h> BOOL APIENTRY DllMain( HANDLE hModule, DWORD ul_reason_for_call, LPVOID lpReserved) { return TRUE; } void F1(void) { MessageBeep(0xFFFFFFFF); }def-файл для dll (можно обойтись и без него, если использовать директиву pragma):
LIBRARY Forward EXPORTS F1 @1 EXPORTS Hi = User32.MessageBoxA @2 NONAMEИ, наконец, код exe, который будет использовать такую хитрую dll:
#include <windows.h> extern "C" int __stdcall Hi(int, char*, char*, int); int main(void) { Hi(0, "Lya-lya-lya", "Test", 0); return 0; }Обратите внимание, в самой dll нет и следа кода форварда, это не является необходимым. Директива Hi = User32.MessageBoxA @2 NONAME предписывает компилятору перенаправить вызов Hi, присвоить этой функции ординал номер два, и сделать так, чтобы в результирующей dll имени функции НЕ было (заметьте, имя функции сохранится в lib, но не будет существовать в dll). В exe файле две директивы extern "C" и __stdcall помогут нам избежать проблем с манглингом функций.
Файл с API-forwarding будет иметь таблицу экспорта с функцией, имеющей нестандартный RVA, значение которого не будет укладываться в лимит размера директории. Алгоритм обработки таких форвардов заложен в функцию LdrpSnapIAT и, как нам кажется, Russell в своей статье здесь допустил ошибку. Смотрите:
NTSTATUS LdrpSnapIAT ... { … // there are forwarders if (-1 != pImageImportDescriptor->ForwarderChain) { IATFirstThunkEntry = pLoadingItem->ImageBase + pImageImportDescriptor->FirstThunk + (pImageImportDescriptor->ForwarderChain / 4); … }Реальный кусочек кода из лоадера (Windows 2000, SP4):
.text:77F99897 mov eax, [ecx+IMAGE_IMPORT_DESCRIPTOR.ForwarderChain] .text:77F9989A cmp eax, 0FFFFFFFFh ; -1 .text:77F9989D jz no_forwarder .text:77F998A3 mov ebx, [edi] .text:77F998A5 lea edx, [ebx+eax*4] .text:77F998A8 mov eax, [ecx] .text:77F998AA add eax, edx .text:77F998AC mov esi, [ecx+IMAGE_IMPORT_DESCRIPTOR.FirstThunk] .text:77F998AF add esi, edxТ.е. не деление, а умножение! Для каждого IMAGE_IMPORT_DESCRIPTOR такой код вызывается единожды. ForwarderChain здесь является индексом первого форварда.
Продолжаем. Если файл привязан к dll, которая загружена по адресу, отличному от ImageBase, привязка перестает быть валидной. В этом случае лоадер будет читать IAT, если не валидна и она – образ загружен не будет.
Время загрузки файла немного уменьшается – это происходит за счет того, что NTDLL.dll уже не патчит адреса внутри модуля, все уже сделано.
При TimeDateStamp равном –1 (т.е. 0xFFFFFFFF) имеем новый стиль привязки.Лоадер сначала проверяет IMAGE_DIRECTORY_ENTRY_BOUND_IMPORT, а только уж потом обращается к IMAGE_IMPORT_DESCRIPTOR (если обращается!). Проведите простой эксперимент: привяжите файл – утилита bind –u filename, потом удалите ВСЕ содержимое IMAGE_IMPORT_DESCRIPTOR, или наполните его мусором. Запустите файл. Ну как? Еще раз повторим. Если не выполняется строгое равенство TimeDateStamp, если файл загружен не на ImageBase, если API адрес не найден и т.п, то мы опять читаем IAT. Поэтому bind отказывается производить привязку образов, не имеющих OriginalFirstThunk – если что-то пойдет не так, мы ведь не сможем восстановиться!
IMAGE_DIRECTORY_ENTRY_BOUND_IMPORT имеет свою структуру:
typedef struct _IMAGE_BOUND_IMPORT_DESCRIPTOR { DWORD TimeDateStamp; //очень разумная мера! /*Откуда, например, лоадер может знать, а не изменилась ли версия dll, к которой привязаны адреса файла? Только сравнивая «временные штампы» библиотек. Если данный TimeStamp совпадает с таковым у библиотеки – все ОК, нет – тогда плохо - выставляется флажок ошибки, и лоадер начинает работу по чтению IID*/ WORD OffsetModuleName; //offset (а НЕ RVA!!!) на имя библиотеки от начала директории WORD NumberOfModuleForwarderRefs; /* Заметьте, это поле – счетчик, указатель количества структур типа IMAGE_BOUND_FORWARDER_REF, которые следуют ПОСЛЕ данной структуры. Строение их абсолютно идентично таковому у IMAGE_BOUND_IMPORT_DESCRIPTOR за исключением поля NumberOfModuleForwarderRefs, которое зарезервировано */ // Array of zero or more IMAGE_BOUND_FORWARDER_REF follows } IMAGE_BOUND_IMPORT_DESCRIPTOR, *PIMAGE_BOUND_IMPORT_DESCRIPTOR;Обратите внимание, что структуры IMAGE_BOUND_IMPORT_DESCRIPTOR и IMAGE_BOUND_FORWARDER_REF в файле перемешаны. Форвард означает, что API как бы «перенаправляется» в другую dll. В ту самую, где, собственно и определен. В этом случае первая dll служит как бы переходником, не более того.
«Живой» пример на нашем неизменном calc.exe выглядит так:
; 1-dec-1999 7:37:27 HEADER:01000238 bound_import_directory dd 3844D037h HEADER:0100023C dw offset на "SHELL32.dll" ;поле содержит 0х38, что прямиком отсылает на к 01000270 (0х38+0х38 == 0х70) ;в IDA жмем G, потом +38 и усе ? HEADER:0100023E dw 0 HEADER:01000240 dd 37F2C227h ; 30-sep-1999 1:51:35 HEADER:01000244 dw offset на "MSVCRT.dll" HEADER:01000246 dw 0 ... HEADER:01000266 dw 0 HEADER:01000268 bound_import_directory_terminator dd 0 HEADER:0100026C dw 0 HEADER:0100026E dw 0 HEADER:01000270 bound_SHELL32_dll db 'SHELL32.dll',0 HEADER:0100027C bound_MSVCRT_dll db 'MSVCRT.dll',0 HEADER:01000287 bound_ADVAPI32_dll db 'ADVAPI32.dll',0 HEADER:01000294 bound_KERNEL32_dll db 'KERNEL32.dll',0 HEADER:010002A1 bound_GDI32_dll db 'GDI32.dll',0 HEADER:010002AB bound_USER32_dll db 'USER32.dll',0Также обязательно необходимо учитывать, что перебазирование dll, к которой привязан данный исполняемый файл (приложение можно "привязать" и к своим библиотекам, bind это позволяет), также повлечет за собой чтение из "старой" директории импорта.
Теперь остановимся на одной грустной-грустной для нас с вами вещи. Положим, мы сдампили программу каким-нибудь дампером, например, LordPE. Положим, также, что некоторые опции утилиты были отключены. Что в этом случае у нас будет с директорией импорта? Предположим, имен и ординалов у нас нет!
Очевидно, файл будет рабочим только при соблюдении одного-единственного непреложного условия – все API-адреса в IAT (FirstThunk) должны быть строго валидными. Шаг в сторону – и такой файл можно просто выбросить. Или нет? Здесь мы подходим к понятию "восстановление таблицы импорта".
Под восстановлением мы понимаем воссоздание массива из структур IMAGE_IMPORT_DESCRIPTOR, обязательно с именами и ординалами. Один из возможных алгоритмов поиска выглядит так. Предполагается, что файл загружен в память и старая директория импорта не является исковерканной.
/************************ * Функция ищет старую таблицу импорта, и возвращает указатель * на первый IMAGE_IMPORT_DESCRIPTOR * Первый параметр это - указатель на память (Memory Mapped Files) * Второй параметр это - размер памяти *************************/ // Процесс этот ресурсоемкий LPVOID FindOldImportTable(LPVOID pMem, DWORD dwSize) { CHAR *szStr; //Тут хранится имя модуля HMODULE hModule; PIMAGE_IMPORT_DESCRIPTOR pIID = {0}; for(DWORD dwRVA = 0; dwRVA < dwSize; dwRVA++) { // Устанавливаем SEH, так как указатель pIID->Name, // иногда ведёт за пределы файла __try { // Получаем структуру IMAGE_IMPORT_DESCRIPTOR по адресу dwRVA pIID = (PIMAGE_IMPORT_DESCRIPTOR)((DWORD)pMem + dwRVA); // Если pIID->Name равно хоть чему нибудь, идём дальше if(pIID->Name) { // Получаем имя модуля по этому адресу szStr = (CHAR*)ImageRvaToVa( ImageNtHeader(pMem), pMem, pIID->Name, NULL); if(!IsBadStringPtr(szStr, 40)) { // Если строка больше 4-х символов, идём дальше. // Почему 4-м? Потому, что ".dll" if(lstrlen(szStr) > 4) { // Загружаем Dll, если загрузилась идём дальше hModule = LoadLibrary(szStr); if(hModule != NULL) { FreeLibrary(hModule); // Выгружаем Dll // Небольшая проверка на валидность структуры if(pIID->TimeDateStamp == 0xFFFFFFFF || pIID->TimeDateStamp == 0x00000000) // Возвращаем указатель // на первый IMAGE_IMPORT_DESCRIPTOR return pIID; } } } } } __except(EXCEPTION_EXECUTE_HANDLER) { // "Access violation" однако. Все равно, продолжаем... continue; } } return NULL; } /************************ * Функция делает простой rebuild, и возвращает размер новой таблицы импорта * Первый параметр это – указатель на память (Memory Mapped Files) * Второй параметр это - адрес возвращённый функцией FindOldImportTable *************************/ DWORD RebuildIT(LPVOID pMem, LPVOID pStart) { PIMAGE_DOS_HEADER pDos = {0}; PIMAGE_NT_HEADERS pNT = {0}; PIMAGE_IMPORT_DESCRIPTOR pIID = {0}; DWORD dwITSize = sizeof(IMAGE_IMPORT_DESCRIPTOR); pDos = (PIMAGE_DOS_HEADER)pMem; pNT = (PIMAGE_NT_HEADERS)((DWORD)pMem + pDos->e_lfanew); pIID = (PIMAGE_IMPORT_DESCRIPTOR)((DWORD)pStart); if(!pIID) return 0; while (pIID->Name) { dwITSize += sizeof(IMAGE_IMPORT_DESCRIPTOR); pIID->TimeDateStamp = 0x00000000; pIID->ForwarderChain = 0x00000000; ++pIID; } return dwITSize; } //Пример использования: DWORD dwMapSize; // Размер памяти LPVOID m_pMap; // Указатель на память (Memory Mapped Files) PIMAGE_DOS_HEADER pDos = {0}; PIMAGE_NT_HEADERS pNT = {0}; ... // Ищем старую таблицу импорта IMAGE_IMPORT_DESCRIPTOR* pIID= (PIMAGE_IMPORT_DESCRIPTOR)FindOldImportTable(m_pMap, dwMapSize); if(pIID) { // Если найдена, делаем rebuild DWORD dwSize = RebuildIT(m_pMap, pIID); if(dwSize > 0) { pDos = (PIMAGE_DOS_HEADER)m_pMap; pNT = (PIMAGE_NT_HEADERS)((DWORD) m_pMap + pDos->e_lfanew); // Устанавливаем RVA таблицы pNT->OptionalHeader.DataDirectory[IMAGE_DIRECTORY_ENTRY_IMPORT].VirtualAddress = (DWORD)pIID - (DWORD)m_pMap; // Устанавливаем размер таблицы pNT->OptionalHeader.DataDirectory[IMAGE_DIRECTORY_ENTRY_IMPORT].Size = dwSize; } } ...Заметим, что данный алгоритм будет работать только на самых простых пакерах (например PECompact), с более продвинутыми, работать уже НЕ будет. Пошла сейчас мода коверкать директорию импорта. И здесь пакеры потихоньку выигрывают, т.к. искалечить всегда легче, чем восстановить. Никаких новых алгоритмов и идей здесь более обсуждаться не будет, т.к. это знание пойдет только во вред ибо может быть использовано авторами пакеров. К нашему глубокому сожалению в сети существуют некоторые проекты по восстановлению директории импорта с открытым исходным кодом, однако это большой недостаток. Уж лучше иметь работающий ImpRec, который худо-бедно но обновляется, чем открытый исходный код с устаревшей, бесполезной идеей.
Теперь рассмотрим, как работать со структурами PE-файла в IDA.
Простите за банальность – IDA – это очень мощный дизассемблер. Практически все операции идут под «капотом». Дизассемблировав PE-файл, вы даже не увидите его заголовков, IDA автоматически прогуляется по всей таблице импорта, все сделано за вас. Это и хорошо, и плохо. Хорошо это тогда, когда нет ни времени, ни желания ковыряться в секциях, просто быстро поломать. Плохо это тогда, когда попадается хитро подправленный файл, который IDA в автоматическом режиме взять не может.
Для примера давайте быстро вручную пробежимся по структурам секции импорта calc.exe. Для начала нам надо найти начало секции таблицы импорта. Итак, быренько запускаем какой-нибудь PE-редактор, например, PE Tools. В PE Editor давим кнопочку Directories. Как вы помните, это массив из #define, где секция импорта идет второй
#define IMAGE_DIRECTORY_ENTRY_IMPORT 1Ее RVA - 12A40. ImageBase файла – OptionalHeader.ImageBase – 01000000, следовательно, в IDA давим G, потом вводим 1012A40 (01000000 + 12A40). Вот прямо с этого места у нас и начинается массив из структур типа IMAGE_IMPORT_DESCRIPTOR.
Выглядит так:
.text:01012A40 db 0C0h ; L .text:01012A41 db 2Bh ; + .text:01012A42 db 1 ; .text:01012A43 db 0 ; .text:01012A44 db 0FFh ; .text:01012A45 db 0FFh ; .text:01012A46 db 0FFh ; ...Обратите внимание на название директории еще раз. Директория будет располагаться внутри секции. Более того, ничто не мешает слить большинство секций файла в одну. Однако мы отвлеклись.
Для того чтобы указать IDA, что тут у нас структура и надо бы преобразовать поля, лезем в Structures. Там создаем Ins структуру тютелька в тютельку по документации из winnt.h:
0000 IMAGE_IMPORT_DESCRIPTOR struc ; (sizeof=0x14, standard type) 0000 OriginalFirstThunk dd ? 0004 TimeDateStamp dd ? 0008 ForwarderChain dd ? 000C Name dd ? 0010 FirstThunk dd ? 0014 IMAGE_IMPORT_DESCRIPTOR endsДалее остается применить эту структуру к смещению 1012A40. Примерно так:
.text:01012A40 dd 12BC0h ; OriginalFirstThunk .text:01012A40 dd 0FFFFFFFFh ; TimeDateStamp .text:01012A40 dd 0FFFFFFFFh ; ForwarderChain .text:01012A40 dd 12CE6h ; Name .text:01012A40 dd 10F4h ; FirstThunkИ так до тех пор пока не попадется IMAGE_IMPORT_DESCRIPTOR, ВСЕ поля которого содержат нули. Аналогичную песню с определением новых структур придется спеть и для IMAGE_THUNK_DATA (а, в случае TimeDateStamp == 0 и для IMAGE_IMPORT_BY_NAME) и т.д., и т.п. А может и не придется! Ведь IDA хранит список стандартных структур! Поэтому, Add struct type > Add standard structure > Search. Но неплохо бы это все дело автоматизировать еще больше! Что ж, не мы с вами такие ленивые. Топаем на datarescue.com/idabаse/idadown.htm и сливаем оттуда PE utilities от Atli Mar Gudmundsson. Необходимо поместить их в %IDADIR%\idc, а потом F2 и файл pe_sections.idc. Если до этого вы не просто читали, а и пытались что-то делать ручками, то будете приятно удивлены.
2.4 Директория ресурсов
Очевидно, что в этой директории программисты хранят иконки, кнопочки, и прочие маленькие радости пользователя. Уже упоминалось, что директория ресурсов обязательно должна размещаться в секции .rsrc, причем имя секции должно быть в точности таким – ".rsrc". Причины уже объяснялись.
Теперь поговорим о восстановлении ресурсов. Для чего это бывает необходимо и каковы здесь технические детали?
Взгляните:
typedef struct _IMAGE_RESOURCE_DIRECTORY_ENTRY { union { struct { DWORD NameOffset:31; //сюда //Обратите внимание - offset от начала секции. DWORD NameIsString:1; }; ... } IMAGE_RESOURCE_DIRECTORY_ENTRY, *PIMAGE_RESOURCE_DIRECTORY_ENTRY; typedef struct _IMAGE_RESOURCE_DATA_ENTRY { DWORD OffsetToData; //и вот сюда // Несмотря на название - это самый типичный RVA DWORD Size; DWORD CodePage; DWORD Reserved; } IMAGE_RESOURCE_DATA_ENTRY, *PIMAGE_RESOURCE_DATA_ENTRY;Здесь хотелось бы процитировать Randy Kath с его статьей "The Portable Executable File Format from Top to Bottom": "The two fields OffsetToData and Size indicate the location and size of the actual resource data. Since this information is used primarily by functions once the application has been loaded, it makes more sense to make the OffsetToData field a relative virtual address. This is precisely the case. Interestingly enough, all other offsets, such as pointers from directory entries to other directories, are offsets relative to the location of the root node."
Да, справедливо то, что полностью уничтожить директорию нельзя и теперь мы знаем почему. Однако, положим, вам пришлось проделать некие хитрые манипуляции с вашим конкретным файлом, например, после распаковки убрать более ненужные секции упаковщика. ОК, вы их убрали и лишились ресурсов, т.к. RVA перестал быть валидным! Значит, надо ресурсы восстановить, т.е. пересчитать смещения. Для этой цели у нас популярным средством является Resource Rebuilder v1.0 by Dr.Golova, а у зарубежных коллег, пожалуй, PE Rebuilder 0.96. О сугубо практическом применении можно почитать здесь - http://xtin.org. Статья - Отрезание секций, перемещение ресурсов, автор Hex.
Восстановление ресурсов, к счастью, не самая сложная процедура. Вкратце, основные принципы таковы:
- Получаем из PE заголовка секцию с именем “.rsrc”.
- Считывается дерево каталогов. Сами данные ресурсов пока можно и не считывать, а считать их на стадии создания новой секции ресурсов.
- Создаём новую секцию ресурсов.
- Подсчитываем необходимый размер будущей секции.
- Далее записываем все ресурсы (каталоги/имена/данные) в эту секцию.
- Затем делается ещё один проход и корректируем все смещения в каталогах.
- Корректируем PE заголовок, если это необходимо.
Здесь алгоритма не будет, так как он очень простой, но большой.
Так же стоит помнить, что и в памяти пакерам не следует грохать заголовок PE-файла (во всяком случае, определенную его часть), т.к. ресурсные API, например, LoadResource, просто перестанут работать. Вероятно, ситуацию можно свести к следующему предположению: если хендл чего-то из PE-файла был получен, то далее эту часть PE-заголовка можно убирать, чтобы затруднить нам жизнь.
Словом, пакеры оставляют все сигнатуры, MZ поле e_lfanew, OptionalHeader.DataDirectory[x] и т.п., но часть жизненно важных данных может быть искажена. Поэтому лучше не играть в кошки-мышки, а просто-напросто в опциях дампера (PE Tools, LordPE) активировать режим вставки заголовка файла с диска (Full Dump: Paste header from disk).
2.5 Директория перемещаемых элементов
Теперь, в довесок к изуродованию директории импорта, секции кода, директории ресурсов и т.п., появляется возможность калечить директорию перемещаемых элементов (relocations, fixups). Например, такой фокус производит UPX (но там открыт исходный код, следовательно, нужно ожидать такого подарочка от многих пакеров в скором времени).
Информация из директории перемещаемых элементов применяется тогда, когда адрес загрузки файла отличается от ImageBase. Для ехе-файлов такое встречается достаточно редко (но не так, чтобы и очень – вспомните VTune), а для dll – это норма. Так вот, директория перемещаемых элементов содержит информацию о том, как патчить данные, расположенные по указанному адресу, чтобы было возможно нормальное продолжение работы. В противном случае, операнд инструкции будет указывать в "космос".
Структура директории выглядит просто:
typedef struct _IMAGE_BASE_RELOCATION { //с этого адреса лоадер должен начинать падчить адреса DWORD VirtualAddress; //размер fixup-блока для данной страницы памяти DWORD SizeOfBlock; // WORD TypeOffset[1]; //тип фиксапа } IMAGE_BASE_RELOCATION;Давайте разберем на живом примере, ЧТО может быть подвержено перемещению и как с этим работать. Итак, создадим простейший файл:
#include <stdio.h> void main(void) { char hello[] = "Name"; printf ("%s", hello); }Только попросим при этом линкер создать исполняемый файл с опцией /FIXED:NO, что означает автоматическое создание директории перемещаемых элементов (как правило, это секция .reloc, хотя и не обязательно). Теперь дизассемблируем в IDA, применяем скрипт от Atli Mar Gudmundsson и смотрим:
loc:1002B000 ; DATA XREF: HEADER:100000D8o ; HEADER:10000298o .reloc:1002B000 relocs_0001_page dd 11000h .reloc:1002B004 relocs_0001_size dd 54h .reloc:1002B008 relocs_0001_toff dw 3A4Fh, 3A58h, 3A64h, 3A78h, 3A9Bh, ... ; ограничено VirtualSize секцииИтак, поле relocs_0001_page, очевидно, соответствует полю VirtualAddress (напоминаем, что релоки применяются к виртуальным страницам, отсюда и слово page), relocs_0001_size - SizeOfBlock, relocs_0001_toff - чуть поинтереснее. Как видим, это массив из word, где старшие четыре бита - это тип релока (в даном случае - #define IMAGE_REL_BASED_HIGHLOW 3), а оставшиеся 12 надо сложить с VirtualAddress, чтобы получить RVA данных для обработки. Ну-ка, давайте посмотрим, куда указывает самое первый word из массива - 3А4F. Итак, A4F + 11000:
.text:10011A4E mov eax, dword ptr ds:aName ; "Name" .text:10011A53 mov [ebp-0Ch], eax .text:10011A56 mov cl, byte ptr ds:aName+4 .text:10011A5C mov [ebp-8], cl .text:10011A5F lea eax, [ebp-0Ch] .text:10011A62 push eax .text:10011A63 push offset aS_0 ; "%s" .text:10011A68 call j__printfБа! Да прямо в центр инструкции mov, т.е. адрес начала массива &hello[0] подвержен обработке! И так много чего. Релокейшенам подвержены строковые литералы, статические переменные, ссылки на неинициализированные статические данные, абсолютные call/jmp, да мало ли что еще! Словом, кошмар!
Релоки обрабатываются лоадером при загрузке – функция - LdrRelocateImage. Обработка релоков происходит перед обработкой таблицы импорта (не всегда!). Функция LdrpMapDll зовет LdrRelocateImage, которая, в свою очередь, определяет заголовок файла, вычисляет где расположена директория релоков и зовет LdrProcessRelocationBlock.
LdrRelocateImage вызывается когда ZwMapViewOfSection (бывшая NtMapViewOfSection) возвращает STATUS_CONFLICTING_ADDRESSES. В случае загрузки по адресу, отличному от ImageBase модуль загружается полностью (обратите внимание, пакер в любом случае обязан пройтись по всем страницам, поэтому запакованный модуль действительно загружается полностью), релоки накладываются сразу, и потом секция с релоками выгружается из памяти (флаг секции IMAGE_SCN_MEM_DISCARDABLE) в своп и в дальнейшем используются только от туда, т.к. из dll Windows более ничего не читает. Что-то отдаленно похожее алгоритмически можно найти в Wine - функция map_image из файла virtual.c. Реальный код из лоадера выглядит так (Win 2000 SP4):
again: mov ecx, [eax+IMAGE_BASE_RELOCATION.SizeOfBlock] lea edx, [eax+_IMAGE_BASE_RELOCATION.TypeOffset] sub [ebp+HMODULE], ecx ; RtlImageDirectoryEntryToData перетирает это значение. ; Теперь оно содержит размер всех релоков ; эквивалентно вычитанию восьми add ecx, 0FFFFFFF8h ; -IMAGE_BASE_RELOCATION = sizeof(Type/Offset entries) push ebx ; Bias push edx ; Type/Offset entries shr ecx, 1 ; Each Type/Offset entry is a word push ecx ; Number of Type/Offset entries mov ecx, edi ; HMODULE ;т.е. прибавить RVA add ecx, [eax+IMAGE_BASE_RELOCATION.VirtualAddress] push ecx ;т.е. имеем VA call _LdrProcessRelocationBlock@16 test eax, eax ; указатель на следующий блок либо ноль jz error cmp [ebp+HMODULE], 0 jnz short againКак вы видите, будут обработаны все блоки перемещаемых элементов, а уж есть ли релоки во ВСЕХ секциях модуля – это совсем другая песня. Сам алгоритм LdrProcessRelocationBlock достаточно тривиален и очень хорошо расписан во многих источниках (www.RSDN.ru, http://mitglied.lycos.de/yoda2k и т.п.), где есть исходники и на C/C++ и на Delphi.
Заметим, что применение релоков чревато не только увеличением времени загрузки, а и частыми page fault - вследствие применения релоков к секции получаем ее копию в памяти - механизм copy-on-write - подробнее MSDN - Ruediger R. Asche - Rebasing Win32 DLLs: The Whole Story.
Итак, мы имеем еще один неутешительный вывод - после применения релоков пакер может эту директорию смело убирать, что он и делает.
Восстановление relocation directory – дело непростое. Стандартной техникой со времен DOS считалась загрузка файла по двум разным базовым адресам, и поиск различий в них (например, по этому принципу работает утилита ReloX от mackT). Для загрузки одного и того же файла его достаточно переименовать, иначе лоадер откажется загружать файл повторно (LdrpCheckForLoadedDll). Заметим, что директория перемещаемых элементов все равно сохраняется под пакером, пусть и в его формате, следовательно, нет принципиальных сложностей в загрузке модуля по двум разным базовым адресам.
Однако в PE Tools используется совершенно безумный алгоритм статического анализа файла, изобретенный NEOx'ом после нескольких бутылок пива (водки?). Итак, основной принцип восстановления релоков – это поиск предположительных ссылок, которые в той или иной степени могут быть подвержены релокам. Ссылки находятся следующим образом:
1) Сканируем все секции от начала до конца (читать данные DWORD-ами, смещаясь на один байт в цикле).
2) Из полученного значения отнимаем OptionalHeader.ImageBase (это нужно для того, чтобы вычислить адрес ссылки)
dwOpcode -= pPeh->OptionalHeader.ImageBase;3) Проверить является ли этот адрес ссылкой, а не кодом. Проверяем – если полученное значение больше OptionalHeader.BaseOfCode, но меньше OptionalHeader.SizeOfImage, значит это ссылка, если нет – читаем следующий DWORD.
if(dwOpcode > pPeh->OptionalHeader.BaseOfCode) if(dwOpcode < pPeh->OptionalHeader.SizeOfImage) { ... //здесь тоже не все так просто! }4) На основе этих данных генерируем новые релоки.
2.6 NTDLL.DLL – Windows Loader
Также необходимо разобраться, что же происходит при загрузке exe/dll в память. Сразу оговорюсь, что процесс этот не будет рассмотрен вообще – не любим повторов.
Для начала необходимо достаточно четко представлять себе архитектуру распределения памяти в Win NT+. Думается, что лучше, чем это сделал Джеффери Рихтер в своей книге "Windows для профессионалов" это не объяснил никто. Такое понимание сильно облегчает жизнь. Например, если вы встречаете нечто вроде адреса 7xxxxxxх, то можете не сомневаться – это адрес какой-нибудь API функции из системных библиотек. Не плохо бы представлять себе и границу стека. ПРИБЛИЗИТЕЛЬНО регион стека в любом вьювере адресного пространства легко опознать по атрибуту страницы PAGE_GUARD. Приблизительно потому, что этот атрибут страницы смещается по стеку во время выполнения.
Загляните в MSDN - статья Q147314 – описание флагов Session Manager. Среди них есть и такой, который требует от NTDLL.dll "озвучивать" свои действия, т.е. выдавать сообщения в окно отладчика (WinDBG, отладчика VS и т.п.). Для того чтобы не морочить себе голову запоминанием флагов, MS создала утилиту GFlags.exe, которая поставляется вместе с комплектом отладочных утилит с сайта MS. Скачать это дело можно совершенно свободно. Мы бы порекомендовали активировать флаг "озвучивания" действий лоадера, т.к. это будет исключительно полезно, например, в тех случаях, когда сдампленная программа не запускается, а лоадер говорит: "Application failed to initialize properly". В этом случае вы сможете быстро найти ту функцию ntdll.dll, которая отказалась "принять" файл и, зная алгоритм ее работы, у вас уже будет какой-то ключик. Это адова работа, но в некоторых случаях такая методика помогает.
Учтите, что ntdll.dll автоматически проецируется на адресное пространство любого Windows-приложения.
Знание работы лоадера часто является абсолютно необходимым. Допустим, у вас есть вопрос, ответа на который вы не нашли ни здесь, ни где-либо еще. Что остается? Дизассемблирование лоадера! Здесь тоже не придется действовать вслепую, уже давно проторены дорожки.
Поверхностно алгоритм работы лоадера расписан на http://www.iecc.com/linker/. Так же алгоритм работы можно приблизительно уяснить из исходных кодов Wine и ReactOS (http://www.reactos.com - своеобразный аналог Wine, только цели чуть другие). Во всем этом деле полезным будет справочник по Native API - http://undocumented.ntinternals.net. Также многие функции лоадера, например RtlImageHeader и т.п., прокомментированы на более высоком уровне в MSDN – библиотека imagehlp.dll.
Для облегчения анализа обязательно сгрузите себе файлы символов – pdb/dbg.
mdsl.microsoft.com Современные утилиты (VS. NET 2003/Driver Studio 2.7+) имеют специальные средства, которые облегчают нам жизнь при копании в недрах Windows. Раньше приходилось топать на http://www.microsoft.com/, и сливать символы ручками, конвертировать их ручками и т.п. Теперь все достаточно просто. В состав DS 2.7 и старше входит утилита Symbol Retriever, которая позволяет сливать символы со специального сервера MS. http://msdl.microsoft.com/download/symbols. Естественно, что и VS .NET 2002/2003 способна обращаться к этому серверу (еще бы!). Достаточно задать в переменных окружения _NT_SYMBOL_PATH, и присвоить ей значение типа
SRV*\\Symbols\Symbols* http://msdl.microsoft.com/download/symbols. Более подробно - MSDN - статьи Джона Роббинса.Самое главное при дизассемблировании лоадера – начинать плясать от определения структур данных. При дизассемблировании файла в IDA вставьте структуры winnt.h (метод описан выше), и начинайте превращать код из неудобоваримого:
mov ax, [edi+4]в
mov ax, [edi+IMAGE_BOUND_IMPORT_DESCRIPTOR.OffsetModuleName]Удачи!
3. 64-bit PE-files
Ну, не так страшен черт, как его малюют. PE файлы изначально проектировались очень разумно, поэтому изменения, связанные с переходом на 64-битную архитектуру, минимальны. С другой стороны – то же все не слишком безоблачно, в первую очередь, из-за типа int64. Но давайте по порядку.
Итак, 64-bit PE файлы еще называются как PE32+. Отличить их от обычного файла можно по сигнатуре. Сигнатура расположена в поле OptionalHeader.Magic и равна
#define IMAGE_NT_OPTIONAL_HDR32_MAGIC 0x10b //PE #define IMAGE_NT_OPTIONAL_HDR64_MAGIC 0x20b //PE32+Для определения типа файла можно использовать эту функцию, которой необходимо передать адрес на проекцию файла:
/*********************** * Return value: TRUE если файл 64-х битный, FALSE если файл 32-х битный * Parameters: pMem - возвращаемое значение от CreateFileMapping, * либо от GetModuleHandle ************************/ BOOL IsPEPlus(LPVOID m_Map) { PIMAGE_NT_HEADERS pNT; pNT = ImageNtHeader(m_Map); if(pNT) return pNT->OptionalHeader.Magic == IMAGE_NT_OPTIONAL_HDR64_MAGIC ? TRUE : FALSE; else return FALSE; }Различий же в строении самих структур (т.е. секций, директорий и т.п.) нет. Естественно, что DWORD заменяется на ULONGLONG, т.е. unsigned int64 (ха-ха!). Разумеется, добавлены новые типы флагов для совместимости, например, с AMD64 и т.п. В директории импорта теперь появляется структура IMAGE_THUNK_DATA64 с типами ULONGLONG, изменения коснулись и ресурсов.
Особо останавливаться на этом не будем.
Такие модули начнут попадаться все чаще и чаще, однако особой паники, думается нам, в этом нет. IDA вполне готова, HIEW грустно говорит об "Unknown header magic" и редактировать поля более не позволяет, LordPE и PE Tools на высоте.
Единственное, что смущает во всем этом деле – так это сам тип int64, а, вернее, его полное отсутствие на 32-битных машинах. Компиляторы просто-напросто эмулируют int64 путем помещения двух DWORD в стек, причем, понятия unsigned int64 пока нет вообще! Словом, у MS ещё не все ладно с поддержкой самого типа. А в будущем… Конечно, проблему решат. Например, переходом на Windows IA-64.
4. Страшное слово XML
Данную главу вы можете смело пропустить на данный момент времени, т.к. создание плагина под PE Tools для генерирования XML-отчета пока только планируется. С другой стороны, данная глава дает очень краткий экскурс в эту несложную, но достаточно специфическую тему, а знание никогда не бывает бесполезным, в особенности в свете того, что имеется тенденция использовать XML-файлы в качестве файлов конфигурации.
Для того чтобы вывести само строение РЕ-файла необходим какой-то очень наглядный формат вывода. Например, такой, в котором мы сможем описывать его структуру и составляющие. Самыми известными являются XML и ASN.1. Последний имеет некоторые преимущества над XML (например, платформо-независимые правила бинарного перекодирования - BER, DER и т.п., хотя с появлением XER - правил бинарного кодирования для XML все немного изменилось), имеет куда более длинную историю развития, но не слишком понятен, громоздок, и, самое главное, многим просто НЕ симпатичен. Поэтому после работы данной программы вы получите XML-файл, описывающий структуру заголовков PE-файла (некоторые поля), и подробно раскрывающий содержание таблицы импорта.
XML – extensible markup language Формат появился на свет не так уж и давно, однако сразу завоевал бешеную популярность. Его активно используют по всему миру как формат обмена данными между программами (различными ОС, приложениями и т.п.). Формат этот платформо-независимый, еще бы, ведь это чистый текст. От HTML внешне он отличается только тем, что название тегов в HTML жестко фиксировано (например, ТОЛЬКО тег <TITLE> и ничто другое не может стоять для вывода информации в строку титула). В XML названия тегов задаю я сам. Получается весьма наглядно и интуитивно понятно.
Например:HTML: <html> <head> <title>PE file format</title> </head> <body> <table> <TR>216</TR> <!—А что такое 216? -!> </table></body> </html>XML:<PE> <IMAGE_DOS_HEADER> <e_lfanew>216</e_lfanew> <!—Ах, да это же содержимое одного из полей заголовка! -!> </IMAGE_DOS_HEADER> </PE>Сравните, как много информации нам дает XML, и как мало – HTML. Да, в первом случае все, быть может, чуть нагляднее представлено браузером, однако во втором – намного более информативно. На каждый XML-документ налагаются достаточно жесткие требования. Как минимум, он должен быть well-formed. Мы бы перевели это как «корректно оформленный» - нельзя делать, например, так:
<PE> <IMAGE_DOS_HEADER> </PE> </IMAGE_DOS_HEADER> <!--должен соблюдаться уровень вложенности!-->Далее, для каждого XML-документа должен существовать (ну, скажем, ЖЕЛАТЕЛЬНО, чтобы существовал) некий словарь, на соответствие которому мы сможем проверить, а правильно ли составлен документ XML (валидность – valid/invalid), т.е. законны или незаконны применяемые теги. Для будущего плагина, без сомнения, будет выбрана проверка в виде XML-Schemas (есть и другие, однако это – самая лучшая).
XML хорош и тем, что позволяет трансформировать документ в другие типы документов при помощи xsl(xslt)-файла. Последний тоже является xml-документом, который представляет собой совокупность директив для программы – XSLT-процессора, принимающей на вход оригинальный XML-файл, и преобразующей его согласно XSLT-файлу. Вывод осуществляется в другой файл или в STDOUT. В качестве замечательного примера такой программы назову XMLSpy (www.altova.com), который позволяет не только применить XSLT к выбранному документу, но и проделать много других вещей, например, проверить на well-formness, валидность и т.п. Более подробно об этом мы поговорим ниже.
Теперь немного о самой будущей программе. NEOx дает возможность создания плагинов под PE Tools, однако, пока совершенно не предоставляет никакого API для удобства работы, а поскольку мы люди ленивые, то пока нету API, нет и плагинов.
Сама программа будет написана на С, т.е. на компилируемом языке, и для своего запуска не требует ничего (кроме Windows). Однако преобразование XML формата в XSLT, выполняемое на С либо даже С++ - занятие нетривиальное! Поэтому для преобразования с использованием XSLT (или XSLT:FO для психов) традиционно используются другие языки. Например, несравненный Perl либо богатейшая библиотека классов Java. Есть, конечно, и MS XML SDK, однако в некоторых случаях лично у нас вызывается жуткое отвращение, в особенности когда MS пытается обозвать свои разработки "стандартом". XML специально разработан так, чтобы разработчики на разных операционных системах могли свободно обмениваться данными. Это гарантируется самой спецификацией XML. MS это пытается нарушить, вводя свои правила. Поэтому, MS XML SDK здесь рассмотрен не будет! Хотя над самой темой обработки XML на С/С++, вероятно, стоит подумать.
Для того, чтобы иметь возможность конвертировать XML в HTML при помощи Perl, вам надо скачать Win32-Perl-интерпретатор (www.activestate.com), проинсталлировать его (а иначе, зачем было качать?), сделать определенные установки и можно начинать работать.
После того, как скачали и поставили дистрибутив Perl, самое время воспользоваться PPM. PPM – это Perl Package Manager – утилита, позволяющая управлять дополнительными модулями. В данном случае нам потребуется модуль Win32API-File, который обеспечивает доступ к некоторым Win32API-функциям работы с файлами. По умолчанию PPM выполняет поиск в так называемых «репозиториях» - одна из них расположена на вашем диске, вторая – в сети на сайте http://www.activestate.com (который, кстати, сильно проигрывает по свежести многим другим зеркалам, позже, мы поговорим об этом).
PPM 3.0.1 PPM – пакет откровенно глюкавый. Что поделать – цена новых необкатанных технологий. Ждем новых версий (почаще заглядывайте на activestate). Посему - НЕ инсталлируйте Perl в директорию, имя которой содержит пробелы (вроде Program Files) – PPM помрет в муках. Инсталлируйте его куда-нибудь вроде C:\Perl, D:\Perl или что-то в этом роде. Массу нервов сбережете! Или, как вариант, можно попробовать VPM из состава Perl Dev Kit. Если уж совсем модуль ставиться не хочет, хоть плачь, то и тогда есть выход – загрузите его вручную, и запустите nmake –install. Только, к сожалению, и здесь камней более чем достаточно. Ну вот, XML-файл готов. Самое время превратить его в HTML. XSL-файл у нас есть (см. приложенный пакет), осталось найти утилиту, которая преобразует полученный XML-файл согласно инструкциям из XSL-файла. Мы возьмем три примера:
- XMLSpy
- VisualXSLT + command-line Perl parser
- Saxon + command-line Java-parser. Сразу скажем, что наиболее просто и приятно использовать XMLSpy. Вес пакета ~ 30 Мб, загрузите его с http://www.altova.com.
XMLSpy – открываете два документа – полученный в результате работы утилиты xml-файл и приложенный XSLT-файл. F10 – и наслаждаетесь полученным HTML-файлом. Можете сохранить. Все. Да, если взбредет в голову проверить на валидность – F8, на корректность – F7. Впрочем, если что-то пойдет не так, вы об этом быстро узнаете.
VisualXSLT + command-line Perl parser – немного более болезненно. VisualXSLT – это модуль к VS.NET. Т.е. у вас должна стоять Visual Studio. Сам пакет брать с activestate. В установках проекта помечаете формат выходного файла, F5 и все. Если парсер запускается из коммандной строки то тогда у вас должен быть собственно сам парсер (приложен). Для работы приложенного парсера требуется библиотека LibXSLT. Ее нужно загрузить из интернета:
http://theoryx5.uwinnipeg.ca/ppmpackages/
Есть такое себе зеркало activestate, которое ведет Randy Kobes (randy@theoryx5.uwinnipeg.ca) – хороший мужик и зеркало очень приличное. Сгружайте оттуда. Заходим в PPM -
ppm> rep Repositories: [1] ActiveState PPM2 Repository [2] ActiveState Package Repository ppm> rep add "Randy" http://theoryx5.uwinnipeg.ca/cgi-bin/ppmserver?urn:/PPMServer58 Repositories: [1] ActiveState PPM2 Repository [2] ActiveState Package Repository [3] Randy ppm> search XML-LibXSLT ... ppm> install XML-LibXSLT ... Successfully installed XML-LibXSLT version 1.53 in ActivePerl 5.8.0.806.Да, если поставили Перл в директорию, имя которой содержит пробелы – несколько приятных часов вам обеспечено %).
Если же модуль по каким-либо причинам ставиться не хочет, тогда топайте на cpan.org и сгружайте его оттуда вручную (если он там есть). Потом вручную настраивайте makefile и потом nmake -install.
Make, чтоб ее... Что тут говорить... Ходят шутки, что даже сам создатель утилиты как-то в слезах признавался, что он больше никогда ничего подобного не сотворит. Видать, боялся, что побьют. И действительно, более неудачное решение трудно себе представить. По сути, make из *nix (и ее аналог от MS – nmake) – это утилита, которая берет на вход makefile из той директории, откуда ее запустили и прорабатывает инструкции, в нем содержащиеся. После чего вы либо с радостью видите готовый exe-файл (что бывает редко), либо с ругательствами принимаетесь разбираться в формате make-файла (что бывает гораздо чаще). Некоторые сторонники make говорят, что это кросс-платформенный вариант, так вот - это ложь. Makefile неизбежно использует ряд платформо-привязанных команд (имя компилятора, директивы командного процессора и т.п.). Кроме того, файл нельзя отлаживать (nmake –n не в счет). В данной статье не будет обсуждаться, что лучше make, однако, посмотрите, например, Ant. А пока, поскольку и Perl использует make (nmake) – на всякий случай приложен маленький симпатичный турториал по makefile, изучив его, вы сможете поправить makefile, если что-то пойдет не так. Также держите в уме, что makefile в процессе создания XS-модуля генерируется автоматически скриптом makefile.pl (точнее, модулем, подключенным к этому скрипту) на основе данных, собранных во время инсталляции дистрибутива. Из этого вытекает, что, хотя генерация makefile абсолютно платформо-независима, но ДАННЫЕ, на основе которых он собирается, ЯВЛЯЮТСЯ зависимыми. Поэтому, скажем, если вы поставили Perl, а потом поменяли, скажем, VS 6.0 на 2002 или 2003, вам не просто придется пересоздавать makefile, но переинсталлировать сам Perl. Теперь вкратце пробежимся по разным XSLT-преобразователям.
Saxon + command-line Java-parser
Для этой бандуры необходим JDK – брать с java.sun.com – он называется J2SE. Сливайте, ставьте и вперед. После установки надо выставить переменную окружения CLASSPATH – для W2k это делается через окошко «Система». Сама CLASSPATH должна выглядеть так: .;C:\путь_к_JDK\lib\tools.jar. Обратите внимание на точку и точку с запятой в начале строки! Также добавьте в PATH путь к JDK. Теперь можно запускать парсер. Парсера звать Saxon – очень навороченная Java-игрушка. Запускать так:java -jar saxon7.jar имя_файла.xsl имя_файла2.xmlНо Saxon большой и качать его долго. Поэтому приложен парсер поменьше и попроще – Stylizer. Скомпилированный файл называется Stylizer.class. Запускать так:
java StylizerОбратите внимание на отсутствие расширения!
Существуют и другие утилиты – например, Xalan. Однако и тех, что здесь перечислены – хватит за глаза.
Единственная вещь, которая может вызывать смущение – это размер XML-файла. Хотя трудно представить себе такой PE-файл, отчет на который займет метров 50 в виде XML, однако… Тогда все xslt-преобразователи благополучно слетят либо с OutOfMemoryException, если это Ява, либо просто помрут в муках, если это С/С++ (потому что чучундры, которые их писали, просто не могли себе представить, что malloc/new может вернуть ноль, кстати, выброс исключения new введен стандартом ANSI-ISO именно поэтому – слишком мало людей озаботились проверить код возврата!). Для столь больших файлов применяется совсем другая схема – пишется разовый SAX-парсер, настроенный на конкретные цели, однако обсуждение этой темы здесь совсем не к месту. Словом, если вам не встретятся файлы отчетов свыше мегабайт, скажем, 30, то и волноваться нечего.
* * *
Ну вот, вроде и все. По идее, теперь вы должны представлять строение PE-файла, уметь играться с Perl и Java, а также приблизительно понимать XML, и уметь применять XSLT. Также, наверняка, вам очень хочется сказать нам что-то теплое, ласковое, домашнее за ваши муки при чтении.
Хотелось бы заметить, что сам характер материала, излагаемого здесь, должен подтолкнуть вас к самостоятельным исследованиям. Нельзя верить тому, что пишут, проверяйте сами! Наверняка большая часть алгоритмов, здесь описанных, в скором времени работать перестанет! Поэтому скажем еще раз - нечего плеваться, если нашли оговорку или опечатку, они неизбежны, несмотря на все наши старания. Все надо проверять!Теперь самое время расстаться с нашими игрушками и рассмотреть реальные случаи.
5. Благодарности
Ну, традиционный пункт, который все авторы старательно пишут, а все читатели старательно игнорируют. Можете игнорировать и вы, кусать никто не будет.
Первым пишу я, Volodya.
Хотелось бы выразить искреннюю благодарность и признательность Евгению Сусликову за данные консультации по RVA/VA и файловым оффсетам. Я также горжусь знакомством со sla-md, который дал мне очень подробные объяснения о преобразовании флагов секций PE-файла в соответствующие атрибуты, объяснил некоторые сетевые трюки и вообще, просто является гениальным человеком. Щiре дякую Quantum'у за успешную попытку статической линковки API-forward-функций. Так же обязательно стоит поблагодарить Russell Osterlund за некоторые пояснения по работе лоадера. Самые теплые слова (эх, как звучит!) надо сказать моей любимой команде - HI-TECH (wasm.ru) - Edmond, Aquila, Broken Sword, Four-F - спасибо за ценные замечания, указания, пожелания, вылавливание мелких и крупных блох в моих рассуждениях. Спасибо!
Вторым пишу я, NEOx.
Хотелось бы выразить особую благодарность Доктору Голове за его консультацию по поводу восстановления директории ресурсов, а так же всей команде uinC.
Итак, что дальше.
Вторая часть статьи будет рассказывать об алгоритмах работы элементарного пакера, самых легких случаях нахождения OEP, распаковке ручками Aspack/UPX/telock/pelock/crunch и т.п. Будет упомянут механизм SEH и некоторые антиотладочные приемы.
Третья часть посвящена очень сложным защитным системам – Armadillo, Obsidium, Asprotect.
Засим разрешите распрощаться до следующей части. Ave.
© Volodya / HI-TECH, NEOx / UINC.RU
Об упаковщиках в последний раз: Часть первая - теоретическая
Дата публикации 11 авг 2003