Написание плагина — эмулирующего отладчика для дизассемблера IDA — Архив WASM.RU
Каждой твари по паре
Каждой виртуальной машине
– по виртуальному процессору
1. Вступление
2. Общее построение
3. Немного об виртуальной памяти IDA
4. Как эмулировать?
5. Об обработчике команд
6. Послесловие
7. Литература1. Вступление
Как-то в Интернете, наткнулся я на отрывок книги Криса Касперски. Вот цитата:
" !IDA DEBUGGER!
В чем новизна и удобство идеи? А в том, что можно сделать не полный, а _контекстный_ отладчик! Что это такое? Обычный дебаpег отлаживает всю программу целиком. Это хоpошо, но чаще всего нас интересуют только выбранные фрагменты. В IDA можно подогнать куpсоp к нужному месту, задать начальные значения pегистpов и пусть на выполнение эмулятоp. Такой подход пpежде всего упоpщает задачу, т.к. тут скоpость не тpубуется. А как удобно! Можно видеть pаботу кода в динамике! И не ломать голову какие будут значения pегистpов\флагов на выходе из такого и такого фpагмента и куда метнеться условный пеpеход. Можно просто прогнать чисто локальный кусок с любой его точки."
Я понимаю, что отладчик для IDA, начиная с версии 4.5 существует, но во-первых не у всех она есть, во-вторых создать отладчик своими руками очень даже интересное дело, поможет поближе ознакомится с устройством IDA и её плагинов. Информация по написанию плагинов для дизассемблера есть в примерах SDK. Сразу надо сказать, что это будет контекстный эмулирующий отладчик 32 разрядного режима. Он будет тесно взаимодействовать с пользователем по части работы. Ну например если эмуляция какой-то команды отсутствует, то предлагается, что пользователь сам проэмулирует её и скорректирует значения регистров, стека.
Предлагаю свой проект, как один из вариантов. Писал я его из-за желания поглубже узнать IDA. Если его довести до ума, то может получится очень полезный program, который может помочь при ручной распаковке и анализе программ.
2. Общее построение
Лучше всего показать на рисунке. В принципе, подойдет не только для отладчика, но и для любого другого плагина.
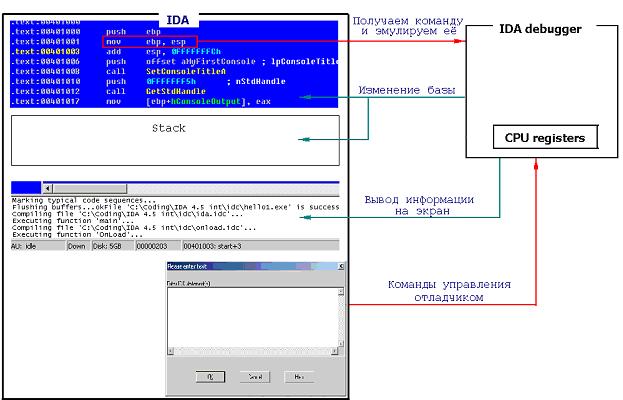
Чтобы можно было корректно эмулировать, надо дополнительно создать сегмент стека в виртуальном пространстве дизассемблера-это необходимо для работы команд со стеком. Как его создать будет показано ниже.
Управление ведется с консоли дизассемблера-как вызов функций. Также можно организовать "горячие" клавиши. Вывод информации на экран - посредством окна сообщений и информативных окошек. Самое интересное - эмуляция команд. После подвода курсора к нужному адресу и ввода начальных значений в регистры, начинается работа отладчика.
В качестве подопытной была взята IDA 4.5 internal (лежала на www.crackbest.com). Также необходим SDK. Без SDK в создании плагинов делать нечего. Команды управления отладчиком были введены при помощи IDC скрипта - "deb_comm.idc". Этот скрипт компилируется во время инициализации плагина (скрипт должен лежать в директории idc дизассемблера), если потерпит неудачу, то можно попытаться загрузить скрипт вручную из меню File\IDC file. Именно в этом скрипте находятся вызовы функций отладчика, можете повесить на функции "горячие клавиши", и добавить новые. Здесь показан формат вызова команды отладчика:
#define MY_FUNC_ID xx static MY_NEW_COMMAND() { RunPlugin("IDA_deb",MY_FUNC_ID); }Которую после добавления в "deb_comm.idc" можно будет вызывать прямо с консоли, например так: MY_NEW_COMMAND(); . Только незабудьте перед этим вставить в функцию run() плагина обработчик этой команды, которая будет обрабатываться, если аргумент будет равен MY_FUNC_ID.
3. Немного об виртуальной памяти IDA
Для написания отладчика надо знать, об виртуальной памяти. Подробнее смотрите "Образ мышления IDA" Криса Касперски. Прошу простить меня за такое представление виртуального адресного пространства IDA и её базы данных, это упрощено, но отладчик работает именно с данными в виртуальной памяти, в которой лежит база данных. На рисунке показано соотношения между адресами (названия взяты от самого создателя IDA):
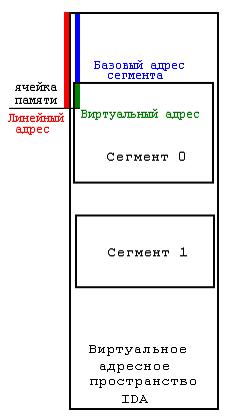
Линейный адрес (тип ea_t) - это адрес в виртуальном пространстве IDA Базовый адрес сегмента - это линейный адрес начала сегмента в виртуальном пространстве IDA Виртуальный адрес - это смещение между линейным адресом и базовым адресом сегмента: Виртуальный адрес=Линейный адрес - Базовый адрес сегмента Как вы уже , наверно, знаете, IDA работает со своим виртуальным пространством, а для дизассемблированной программы создаются сегменты со своими атрибутами (база, селектор разрядность и.т.п.), и с ним же будет работать и наш отладчик, через функции get_byte(..), get_word(), get_long, patch_byte, patch_word, patch_long - все они определены в BYTES.HPP, и там ещё много интересного есть. Линейный адрес вычисляется как
(Base<<4+смещение), где Base - база сегмента4. Как эмулировать?
Думаю, для этого нужно узнать, как работает то, что мы будем эмулировать - т.е. центральный процессор. Если заглянуть в талмуды Intel, то можно найти примерно следующую последовательность действий по исполнению инструкций:
Like the Intel486 CPU, integer instructions traverse a 5 stage pipe-line. The pipe-line stages are as follows:
PF Prefetch D1 Instruction Decode D2 Address Generate EX Execute - ALU and Cache Access WB Writeback
Т.е -предвыборка команды -декодирование команды -генерация адреса, для определения адреса операндов в памяти -выполнение опреаций с помощью АЛУ запись результатаПридержимся этой последовательности и мы. Посмотрите на вариант эмулятора инструкций. Предвыборку, дешифрацию команд уже сделала IDA, нам остается только разобраться в операндах и вызвать обработчик команды.
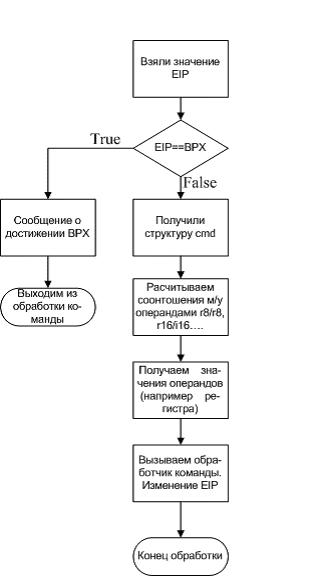
Чтобы приступить к непосредственной эмуляции, давайте разберемся, как IDA хранит инструкции. Для этого имеются несколько структур, они описаны в файле INCLUDE\UA.hpp. Этот файл ОЧЕНЬ важен при написании эмулятора, т.к. в нем описывается формат данных команды, её операндов их типы.
// Хранит информацию о команде idaman insn_t ida_export_data cmd; // текущая инструкция // Класс описывающий инструкцию (сокращено) class insn_t { public: ushort itype; // Код инструкции (Инициализируется в 0 ядром // IDA все инструкции содержатся в директории // INCLUDE\allins.hpp ulong cs; // База сегмента, в котором находится // инструкция (Инициализируется ядром IDA ulong ip; // Виртуальный адрес инструкции (адрес ВНУТРИ // сегмента) блин, от этих виртуальных адресов // уже сам начинаешь виртуалиться //(Устанавливается ядром // ИДА, а кем-же ещё) ea_t ea; // Линейный адрес инструкции ushort size; // Размер инструкции в байтах // Сведения об операндах инструкции #define UA_MAXOP 6 op_t Operands[UA_MAXOP]; // Массив содержит структуру описывающую каждый // операнд в команде. К нему удобно обратится #define Op1 Operands[0] // ,например, так: op_t x= cmd.Op1-получаем ин- #define Op2 Operands[1] // формацию об первом операнде (странно, что не #define Op3 Operands[2] // нулевой) #define Op4 Operands[3] #define Op5 Operands[4] #define Op6 Operands[5] }; // Класс - тип операнда, (показано неполностью) class op_t { public: char n; // Порядковый номер операнда // Структура описывающая тип операнда (очень интересное поле) optype_t type; // Тип значения операнда char dtyp; #define dt_byte 0 // 8 bit #define dt_word 1 // 16 bit #define dt_dword 2 // 32 bit #define dt_float 3 // 4 byte #define dt_double 4 // 8 byte #define dt_tbyte 5 // variable size (ph.tbyte_size) #define dt_packreal 6 // packed real format for mc68040 #define dt_qword 7 // 64 bit #define dt_byte16 8 // 128 bit #define dt_code 9 // ptr to code (not used?) #define dt_void 10 // none #define dt_fword 11 // 48 bit #define dt_bitfild 12 // bit field (mc680x0) #define dt_string 13 // pointer to asciiz string #define dt_unicode 14 // pointer to unicode string }; Ну и, наконец, описание типа операнда typedef uchar optype_t; const optype_t // Поле в op_t o_void = 0, // нет операнда ---------- o_reg = 1, // Основной регистр (al,ax,es,ds...) reg o_mem = 2, // Прямое обращение к памяти addr o_phrase = 3, // Memory Ref [Base Reg + Index Reg] phrase o_displ = 4, // Memory Reg [Base Reg + Index Reg + Displacement] phrase+addr o_imm = 5, // Непосредственное значение value o_far = 6, // Непосредственный дальний адрес addr o_near = 7, // Непосредственный ближний адрес addr o_idpspec0 = 8, // IDP specific type o_idpspec1 = 9, // IDP specific type o_idpspec2 = 10, // IDP specific type o_idpspec3 = 11, // IDP specific type o_idpspec4 = 12, // IDP specific type o_idpspec5 = 13, // IDP specific type o_last = 14; // first unused type char specflag1; char specflag2; char specflag3; char specflag4; }В структуре optype_t есть следующие поля:
char specflag1;
char specflag2;
char specflag3;
char specflag4;
Эти флаги заполняются ядром ИДА (точнее процессорным модулем). Как заполняются не сказано, но, проведя эксперименты, с различными инструкциями и способами адресации, удалось выяснить вот что:
Флаг specflag1 и все остальные равен нулю если:
1. Имеется прямая адресация (OpX.type=o_mem). Т.е. например mov eax,[401000]
2. Косвенная адресация (OpX.type=o_phrase) mov eax,[eax]
3. Косвенная адресация со сдвигом (OpX.type=o_displ) mov eax,[eax+402031]
Если specflag1==1, то в specflag2 содержится информация об составляющих операнда (например при индексной адресации с масштабированием) Если OpX.type=o_phrase, то specflag2 будет расшифровываться так:
Кодировка регистров в точности, как принята у Intel:
Коэффициент масштабирования определяет степень двойки, на которую нужно умножить значение индексного регистра:
Например :
lea eax, [ebx+ecx*4] Op2 type is: 3 Op2 dtyp is: 0 Op2 value is: 0 Op2 reg is: 4 Op2 phrase is: 4 Op2 address is: 0 Op2 offb is: 0 Op2 offo is: 0 Op2 specflag1 is: 1 Op2 specflag2 is: 9B Op1 specflag3 is: 0 Op2 specflag2 is: 9B 10001011 10-4 011-ebx 001-ecxЕсли OpX.type=o_mem, то specflag2 будет расшифровываться так:
Если OpX.type=o_displ, то specflag2 будет расшифровываться так:
Также в этом случае, в поле OpX.addr, будет находится значение смещения
Однако здесь есть одно исключение для обращения к памяти вида: [esp+xxx] В этом случае specflag1=1; specflag2=0x24
Разберемся с сегментами IDA. Сетменты в IDA-один из её краеугольных камней. И надо ознакомится со структурами, которые их описывают: Нам они понадобятся для создания сегмента стека отладчика. Без него работать, мягко говоря некорректно. Каждый сегмент имеет базовый сегментный адрес, который определяет положение сегмента в виртуальной памяти IDA. В поле Base может находится базовый адрес, а может находится индекс селектора. Селектор содержит 32-битный базовый адрес сегмента в виртуальном пространстве IDA. Подробнее смотрите "Образ мышления IDA" Криса Касперски.
Данные и функции работающие с сегментами содержатся в заголовочном файле SEGMENT.HPP . К сегментам можно обращаться разными способами. Тип структуры, описывающею сегмент segment_t. В ней содержится вся информация о сегменте: База, начальный адрес, конечный адрес, имя сегмента, выравнивание сегмента, разрядность 16 или 32 бит, и.т.д.
class segment_t : public area_t { public: long name; // имя сегмента long sclass; // класс сегмента long orgbase; // это поле зависит от IDP uchar align; uchar comb; // Код комбинирования сегмента с другими uchar perm; // "Разрешение" сегмента (EXE, READ, WRITE) uchar use32; // разрядность сегмента ushort flags; // флаги сегмента sel_t sel; // селектор сегмента uchar type; // Тип сегмента };Вот как примерно выглядит создание сегмента стека для отладчика. Подробное описание функций смотрите в SEGMENT.HPP
// Находим пустой селектор и проецируем на виртуальную память // N - селектор для сегмента sel_t N=allocate_selector(0); // Создаем сегмент if(add_segm(N,0xFFFF0000,0xFFFFFFFE,"STCK","STACK")) { segment_t DEBUGGER_STACK_SEGMENT, *pDSS; pDSS = &DEBUGGER_STACK_SEGMENT; pDSS = get_segm_by_sel(N); set_segm_addressing(pDSS,1); msg("Debugger stack created\n"); } else warning("Cant create segment\n");Как видите, ничего сложного нет.
5. Об обработчике команд
В эмуляторе всю работу по исполнению инструкций выполняют обработчики команд. Было решено в обработчик передавать тип соотношения операндов (например: один операнд - регистр, один операнд в памяти, один регистр - другой в памяти). В исходниках это выполняет функция get_operand_info(OPER &), которая заполняет структуру OPER. Также она заполняет поля структуры: вычисленными значениями операндов (например, при косвенной адресации). Сам обработчик команды знает о том какие операнды и какие сочетания операндов возможны и в зависимости от этого выполняется. Покажу на примере инструкции push:
// push instruction BYTE emPUSH(OPER &O){ // Выводить о работе команды, как вы понимаете не обязательно. // Просто удобно при отладке обработчика msg("This is a PUSH cmd emulation\n"); // В стеке есть место?? if(!checkESP(-4)) return false; // Проверка, если один из операндов в памяти, на принадлежность к // несуществующему адресу. if(!checkEA(O)) return false; EIP2NextCmd(O); // Операнд один - непосредственное значение 32бит if(O.rel==i32) { *pemESP-=4; //Уменьшили ESP return (WriteVMDWORD(*pemESP,O.op0_i32));//Пишем в вирт. память } // Операнд один - непосредственное значение 16бит if(O.rel==i16) { *pemESP-=2; return (WriteVMWORD(*pemESP,O.op0_i16)); } // Операнд один - непосредственное значение 8бит if(O.rel==i8) { *pemESP-=2; return (WriteVMWORD(*pemESP,(WORD)O.op0_i8)); } // Здесь должна быть проверка на опернды - регистры и операнды, находящиеся в // памяти // if(O.rel==r32). . . // if(O.rel==r16). . . // if(O.rel==m32). . . // if(O.rel==m16). . . // Если мы здесь, то операнды неопознаны warning("UNKNOWN OPERAND IN PUSH CMD"); return INS_BAD_OP; }Это одна из "частных" инструкций и для других писать обработчик намного проще. Например эмуляция инструкции cmp
// cmp void __declspec(naked) emCMP8() {_asm {cmp al,bl retn} } void __declspec(naked) emCMP16(){_asm {cmp ax,bx retn} } void __declspec(naked) emCMP32(){_asm {cmp eax,ebx retn} } /////////////////////////////////////////////////////// // cmp /////////////////////////////////////////////////////// bool emCMP(OPER &O){ if(!checkEA(O)) return false; EIP2NextCmd(O); return two_op_handle(O, emCMP8, emCMP16, emCMP32); }Вот и весь обработчик инструкции. Вся работа будет происходить в two_op_handle, которая и учтет типы операдов их типы, и воздействие на флаги.
Перед написанием обработчика инструкции, неплохо бы узнать, что возвращает структура cmd , так как может отличаться для разных инструкций. Например для инструкции lea eax,[ebx] cmd.Op1.dtyp = dt_dword, а cmd.Op1.dtyp = dt_byte. Поэтому ,возможно, придется добавить обработку ситуации в функцию get_operand_info.При написании обработчиков ОЧЕНЬ неплохо помогает справочник из книги Юрова "Ассемблер", там расписаны все типы операндов команд и алгоритм их работы.
6. Послесловие
На данный момент поддерживается:
1) Точки останова BPX,
2) BPM_R, BPM_W, BPM_RW
3) Эмулировано 122 инструкции x86 (кроме 3-х операндных imul, shld, shrd, enter, leave и др., их можете реализовать сами.)Команды управления отладчиком можно уточнить как help(); из консоли IDA.
Надо добавить: 1) Создать нормальный показ регистров в отладчике в виде отдельного диалогового окна
2) При желании можно добавить эмуляцию FPU, MMX
Самое серьезное, что непонятно, как эмулировать вызовы WinAPI функций. Похоже, что неполучится, но в принципе в контекстном отладчике это и ненужно, хотя было бы неплохо.В приложении содержится исходный код отладчика, а также скомпилированная версия плагина для IDA 4.5 Похоже, что файл plugins.cfg необязателен (ИДА 4.5), т.к. и без него плагин вызывался нормально. Подозреваю, что ИДА сканирует директорию с плагинами и узнает параметры через структуру PLUGIN. Если неполучится, то добавьте следующую строку:
CDEx86 CDEx86 F11 0
, также можно добавить горячую клавишу к плагину.Первые шаги по работе:
1) Скопируйте CDEx86.plw в папку \plugins дизассемблера.
2) Запустите дизассемблер
3) Приведите курсор к куску кода, который хотите изучить, и начинаите трассировку ( по умолчанию клавиша F11)
4) Значения регистров можно посмотреть вызвав r(); из консоли (Shift+F2). В следующей версии ,возможно, будет отдельное окно с регистрами.
5) Если хотите автоматическую трассировку, то подведите курсор к месту, где должна остановится трассировка и введите из консоли точку останова.
bpx();
at();Точно так устанавливаются виртуальные бряки на чтение\запись в память bpm();
Поработав со своим творением, у меня появились некоторые рекомендации по работе с ним:
1) Отладчик предполагает хорошие навыки работой с IDA.
2) Не надо лезть в вызов WinAPI функции, т.к. ее кода нет в дизассемблере и соответственно нельзя ее трассировать. Лучше всего перепрыгнуть её ( cheip(); ), сбалансировав стек.
3) Отладчик получает инструкцию по адресу курсора IDA. Поэтому если вы прыгнете на середину команды, то получите сообщение Not code. Stay at code first. В этом случае надо сперва превратить в Unknown, а затем превратить в Code.
4) Необходимо создать окно, в которое выводить информацию. В первую очередь - значения регистров Т.к. неудобно каждый раз вызывать команду r();
Ненадо требовать от контекстного отладчика сверхъестественного. Я писал его лишь из-за интереса к внутреннему устройства IDA. Если чего-то нехватает, добавьте сами - исходники есть.
Во время работы с плагином, появилась идея использовать его для ручной распаковки програм:
Алгоритм примерно выглядит следующим образом:
1. Загружаете файл как бинарный
2. Применяете PE_scripts by Atli Gudmundsson (есть на wasm.ru)
3. Пробуете трассировать его с точки входа
4. Сохраняете на диск заголовок и секции при помощи скрипта pe_write.
(А еще лучше написать свой. Т.к. больше шансов получить работоспособный файл)И напоследок, хотелось бы сказать большое спасибо Крису Касперски, за его отличные книги и статьи.
, а также создателям WASM.RU за то, что есть такой замечательный ресурс7. Литература
1. pilorama.com.ru
2. Юров В., Хорошенко С. Ассемблер: учебный курс
3. Зубков С.В. Ассемблер язык неограниченных возможностей
Жду поправок и более крутых решенийИсходник к статье. © Rustem
Написание плагина — эмулирующего отладчика для дизассемблера IDA
Дата публикации 8 мар 2004
