Процессор изнутри. Часть 4: AMD64 — Архив WASM.RU
Процессор изнутри. Часть 4: AMD64
Процессор Athlon-64 является первым массовым 64-разрядным процессором для настольных систем. За счет этого он немного выбивается из ряда всех рассматриваемых нами процессоров. Но поскольку он предоставляет средства мониторинга производительности, было бы неуважением по отношению к AMD обойти его вниманием.
Большинство событий, которые описаны ниже, поддерживаются также и в Athlon XP. Не поддерживаются только события связанные с HyperTransport и FPU.
Интерфейс процессора.
Процессор Opteron использует встроенный в ядро контроллер памяти, что является беспрецедентным случаем во всей истории x86-совместимых процессоров. Естественно, что это самым значительным образом отразилось на интерфейсе процессора и системы. На рисунке слева показана базовая архитектура однопроцессорной системы, а справа – на базе Opteron/Athlon-64.
Память теперь во всех смыслах «ближе» процессору. Насчет оптимальности этого решения можно еще поговорить – с одной стороны достигается повышение производительности за счет того, что контроллер работает на частоте ядра и оптимально «заточен» под конкретное ядро самой AMD, а с другой стороны, возможно использование только одного типа памяти. В случае если появится какой-то новый тип памяти, несовместимый с DDR SDRAM, для остальных процессоров просто появятся новые северные мосты, а AMD придется переделывать ядро.
Шина HyperTransport.
Сразу предупрежу, что шина Hyper Transport является довольно сложной вещью, и полностью рассматривать ее здесь мы не будем. Кому интересно, могут зайти на сайт консорциума HyperTransport Consortium (http://hypertransport.org если не заходит так, попробуйте с www) и скачать там полный мануал в 300 с чем-то страниц.
Шина Hyper Transport, в отличие от других шин, применяющихся в качестве системной шины процессора, является пакетно-ориентированной. Это значит что устройства, подключенные к шине, обмениваются пакетами, имеющими фиксированные форматы для каждого типа обмена. Это ключевой момент.
Если в других шинах, передачи данных и адресов в общем случае не зависят друг от друга, и правильная их передача обеспечивается благодаря жёсткой синхронизации, то здесь достаточно одной синхронизирующей линии, по которой синхронизируется передача пакета. Таким образом, данные и адреса жёстко привязаны друг к другу, так как находятся в одном пакете.
Основными сигналами являются всего 3 набора линий:
CAD
Control, Address, Data – по этим линиям передаются все пакеты.
Шина может насчитывать от 8 до 32 линий.
CTL
Control - Флаг, указывающий на то, что передается управляющий пакет.
CLK
Clock - Синхронизация.
Нужно еще немного пояснить назначение сигнала CTL. О том, что данный пакет – управляющий, получившее его устройство узнает из полей пакета, передатчик тоже знает, что этот пакет управляющий. Казалось бы, что этот сигнал лишний. На самом деле, он применяется несколько по-другому – если во время передачи длинного пакета данных источнику вдруг понадобится быстро передать управляющий пакет, скажем сведения о возникших ошибках или еще какую-то важную информацию, которая не может ждать, источник устанавливает сигнал CTL, чем прерывает передачу пакета данных и начинает передачу управляющего пакета.
Набор из этих 6-и сигнальных линий (по 3 в каждую сторону) называется линком HyperTransport.
Имеются также несколько сигналов для управления энергопотреблением, сброса шины и т.д.
LDTSTOP#
Включает/выключает линк в течение системных транзакций.
LDTREQ#
Сигнализирует об активности линка.
PWROK
Питание в норме, входящий сигнал для устройств.
RESET#
Сброс шины.
Каждый из этих сигналов требует одной линии.
Сигналы линий CLK применяются только для синхронизации передачи пакета. Синхронизация устройств на шине осуществляется с помощью специальных синхронизирующих пакетов (sync packets).
В виде пакетов передаются даже такие вещи как запросы прерываний и EOI (End Of Interrupt).
Также применяется немного нестандартный механизм адресации – имеется 64 бита адреса, это огромное адресное пространство разделено на части.
Часть с 0000_0000_0000_0000h по 0000_00FC_FFFF_FFFFh применяется для адресации памяти, часть с 0000_00FD_FC00_0000h до 0000_00FD_FDFF_FFFFh для пространства ввода-вывода и так далее.
HyperTransport изначально разрабатывалась с прицелом на многопроцессорные системы.
Более того, к шине могут подключаться не только процессоры, но и другое оборудование, аналогично шине PCI.
В адресном пространстве HyperTransport выделена область размером в 32Мб для доступа к конфигурационному пространству устройств. Само конфигурационное пространство по формату аналогично PCI. Любое устройство, подключаемое к шине должно иметь PCI-подобный заголовок, в котором указываются производитель устройства, некоторые параметры и т.п.
Шина поддерживает виртуальные каналы, маршрутизацию и т.д. Рассмотрение всего этого подходит для отдельного мануала, поэтому на данном этапе закончим обсуждение HyperTransport.
Кэширование.
Кэширование, как и в Athlon XP, включает в себя разделенные кэши для данных и кода первого уровня и общий кэш L2. TLB также разделены на 2 уровня.
Кэши обоих уровней реализуют все тот же протокол MOESI для обеспечения мультипроцессорной когерентности.
Кэш, как L1, так и L2, поддерживают контроль и исправление ошибок, как в полях данных, так и в полях тэгов.
Ядро.
Структурная блок-схема процессора приводится ниже, она сильно напоминает блок-схему Athlon, особенно в части исполнительных устройств и диспетчеризации команд.
В целом, схема выполнения команд не претерпела значительных изменений по сравнению с Athlon XP – выборка, декодирование в макрооперации, планирование, декодирование в микрооперации, исполнение, восстановление.
Ключевыми свойствами архитектуры являются шина HyperTransport, встроенный в ядро контроллер памяти и аппаратная поддержка 64-битых операций.
В предыдущей части я обещал подробнее рассказать про таблицу GHBC и как она используется при прогнозировании переходов.
Чтобы понять, как она работает, нужно ввести такое понятие как регистр глобальной истории переходов GHR (Global History Register). Он представляет собой обычный регистр некоторой разрядности N. Каждый переход, декодируемый процессором, вызывает сдвиг этого регистра влево на 1 бит. После проверки условия перехода, когда команда перехода доходит до стадии retirement, младший бит регистра (соответствующий этому переходу) устанавливается в соответствии с условием перехода – в 1, если переход произошел и в 0, если нет (это условно, ничто не мешает сделать наоборот).
Регистр, таким образом, отражает историю исполнения последних N условных переходов, или как принято говорить – шаблон истории переходов (branch history pattern).
Таблица GHBC устроена в теории следующим образом, каждая строка соответствует одной команде условного перехода, индексом по строкам является младшая часть адреса команды.
Индексом же по столбцам является сам регистр GHR.
В таблице хранятся двухбитовые счетчики, эквивалентные счетчикам, хранимым в BTB, только для предсказания ветвлений используются разные счетчики в зависимости от исполнения предыдущих команд условных переходов, так как в качестве индекса используется GHR.
Это лучше показать на примере. Скажем, какая-то команда I выполняется, только если команда перехода I-1 произошла, а I-2 и I-3 – нет.
В случае выполнения такой последовательности, благодаря GHR будет использоваться та ячейка GHBC, которая будет содержать счетчик, используемый только при таком развитии событий (только при такой истории переходов).
В случае же если вдруг условие предыдущих команд не выполнилось, будет использоваться другой индекс GHR и другой счетчик. Даже если до этого переход исполнялся 100 раз, в 101-ый раз процессор может предсказать, что он не произойдет, основываясь на истории предыдущих команд. Таблица BTB на это не способна, если переход происходил более 2-х раз, для 3-го раза процессор тоже предскажет, что он произойдет.
Это теория. На практике получается немного не так. Дело в том, что в мануале по Opteron указывается, что в GHR учитывается исход 8-и последних команд, и для индексации таблицы используются 4 бита адреса команды. При этом говорится, что таблица имеет 16384 входа (или другими словами – 16384 ячейки).
Проблема в том, что для индексации 16К счетчиков недостаточно 12 битов (8 бит GHR + 4 бита адреса).
Получается, что либо для индексации таблицы используется еще что-то имеющее разрядность 2 бита, либо таблица имеет размерность 4096 счетчиков.
Если у кого-то есть более точная информация по данному поводу, большая просьба выслать мне линк или саму документацию.
Как и для предыдущих процессоров рассмотрим путь команды из памяти до стадии retirement.
Все запросы процессора к системе попадают в очередь запросов SRQ (system request queue), и оттуда обслуживаются через шину HyperTransport.
Выборка осуществляется стандартным путем – из instruction-L1.
В случае удаления строки из L1 в L2 то вся информация преддекодирования также сохраняется в L2.
На этом же этапе происходит прогнозирование переходов и предвыборка следующих команд. Далее команда попадает в декодер, который преобразует команду в макрооперации.
Они попадают в ICU который почему то на рисунке не показан, но обсуждается в мануале, ICU выполняет все то же что и в Athlon – переименование регистров, планирование.
Затем, макрооперации, как и ранее, попадают в планировщики, которые содержат внутренние буферы (резервационные станции), планировщик осуществляет дальнейшее декодирование в микрооперации и исполнение соответствующим исполнительным устройством.
Выходные шины всех исполнительных устройств заведены, опять же, как в Athlon, на LSU (ICU указывает, в какую ячейку следует поместить результат) в котором хранится результат команды до выполнения ее восстановления (LSU блок-схеме процессора не показан, но, как и ICU обсуждается в мануале).
Восстановление стандартно – запись результата в постоянные регистры, инкремент EIP на длину команды и удаление команды из ICU и других буферов.
Для тех, кто читал предыдущие части мануала (в частности про Athlon) не составит проблемы понять, как работает процессор, поэтому не будем подробно обсуждать еще раз то, что уже обсуждалось.
Мониторинг производительности.
В плане мониторинга производительности процессоры Opteron/Athlon-64 частично совместимы с Athlon XP/Duron. Частично, потому что форматы регистров и номера MSR не отличаются, но списки событий разные. То есть программа, работающая с Athlon, не будет shutdown-ить новый процессор, но не факт что счетчик будет считать то, что вам надо. Формат управляющих регистров счетчика:
Не могу удержаться, чтобы не похвалить AMD за такую заботу о программистах. После заумных механизмов Pentium 4, увидев механизм мониторинга Opteron, сразу проникаешься уважением к людям проектировавшим последний.
Еще один нюанс, по маске события теперь можно узнать устройство, к которому относится данное событие, что является нововведением.
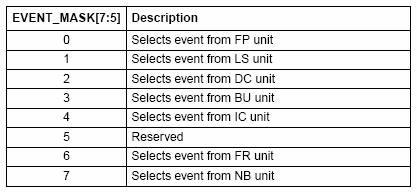
Так события с масками 81h и 41h называются абсолютно одинаково – miss (промах).
Но первое имеет 3 старшие бита равные 100b, а второе – 010b.
По таблице находим, что источником первого события является IC (instruction cache), а второго – DC (data cache).
Таким образом, первое событие – промах instruction-L1, а второе - data-L1.
Processor spy.
Помните, в предыдущей части, посвященной Athlon, я говорил, что если бы в Athlon добавить больше событий, то было бы вообще хорошо. Так вот, в Athlon XP и Athlon-64 AMD что называется «оторвалась по полной программе» - процессор поддерживает мониторинг свыше 70 событий, и это при том, что механизм программирования счетчиков остался тем же.
По моему, данный процессор обладает самым лучшим механизмом мониторинга производительности, если смотреть по отношению - удобство_программирования/количество_событий.
Файлы: athlon64.zip · amd64.zip © Dark_Master
Процессор изнутри. Часть 4: AMD64
Дата публикации 9 мар 2005






