Исследование «промежуточного» кода на примере GP-кода языка NATURAL — Архив WASM.RU
После такого заголовка я, как "порядочный мужчина", просто обязан объяснить, что имел в виду, называя так статью, о чем, зачем и для кого она написана.
Начнем с главного.
Зачем и для кого написана эта статья?
В этой статье я бы хотел поделиться своими результатами в исследовании "промежуточного" кода. Я вполне отдаю себе отчет в том, что исследование скомпилированного кода малоизвестным компилятором, да еще и требующего интерпретатора для своего исполнения, едва ли вызовет широкий интерес. Но все же я решился на публикацию, и вот по каким причинам:
- Эта статья может быть интересной малочисленным программистам, специализирующимся на Natural, и желающим поднять свою квалификацию. Думаю, понимание того, во что превращается исходный код при компиляции, будет способствовать этому росту.
- Эта статья может помочь также в случае необходимости восстановить исходный код из "промежуточного" (опять-таки для Natural-программистов).
- Эта статья может быть полезной для исследователей, изучающих какой-то свой специфический псевдокод, по которому нет информации ни из официальной документации, ни от коллег-исследователей.
- Надеюсь, статья может стать интересной и для программистов, разрабатывающих свой язык/интерпретатор (если такие еще найдутся).
Промежуточный код
Существует множество терминов, означающих приблизительно одно и то же. Псевдокод, псевдокомпилированный код, промежуточный код - все это одного поля ягоды. Мне больше нравится термин "промежуточный код" - в виду отсутствия четких общепринятых определений могу себе позволить выбирать по своему усмотрению.
Как правило, промежуточный код более компактен, чем исходный код, за счет удаления в процессе компиляции (или псевдокомпиляции, если хотите) всяких излишеств - комментариев, пустых строк и т.д., а так же за счет преобразования имен переменных в адреса, а "человеческих" операторов в инструкции, понятные интерпретатору. Очевидно, промежуточный код должен быть структурирован так, чтобы его исполнение интерпретатором было максимально эффективным.
Существует два крайних подхода к исследованию промежуточного кода:
- исследование работы компилятора и интерпретатора (инструменты - дизассемблер, отладчик);
- метод "черного ящика" (инструменты - голова и hex-редактор). "Черным ящиком" опять же может быть как компилятор (вход - исходный код программы, выход - промежуточный код), так и интерпретатор (вход - промежуточный код, выход - результат выполнения программы).
Наиболее эффективным, конечно же, является их комбинация, поэтому мы попробуем и то, и другое… и третье - в предыдущей статье ("Тайна золотого ключика…") я уже напоминал о "бонусах" от SAG'а, не обошлось без них и на этот раз. Но об этом ниже.
NATURAL и GP-код
Сейчас под именем Natural (начиная с 4 версии) скрывается и интегрированная среда разработки (Natural Studio), и язык программирования. Разработчик - немецкая компания Software AG (коротко SAG).
Языку уже более четверти века - его начали разрабатывать в 1976 и в 1979 он был выпущен на рынок. В те времена его называли "языком манипулирования данными". Он "крутился" на мэйнфрейме и был логическим продолжением БД ADABAS (разработчик - та же компания, SAG). Сейчас же это не иначе как "мощный сервер приложений компании Software AG, позволяющий разработчикам быстро создавать критически важные приложения". Эта штуковина работает на мэйнфреймах, на *nix и на Windows - платформах. Гарантируется переносимость на уровне исходных кодов с одной платформы на другую (если хорошенько подработать напильником). С 5-ой версии (на момент написания статьи последняя версия Natural - 6-ая) была заявлена переносимость т.н. "сгенерированных программ" (generated programs, GP, проще - скомпилированных программ) между *nix и Windows - платформами. В ближайшем будущем анонсируется переносимость GP-кода и на мэйнфрейм - платформы.
Как и всякий промежуточный код, GP-код не самодостаточен - он может быть исполнен лишь при наличии интерпретатора.
Переносимость того самого "промежуточного" кода, о котором мы говорили выше, да тем более между "открытыми системами" и мэйнфреймами - это уже интересно!
Часть 1. Определение общей структуры GP-кода
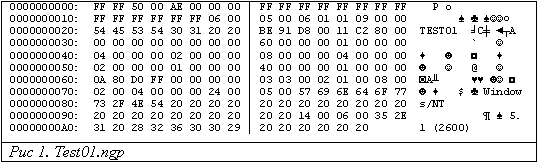
Первое, что приходит на ум (и не самое лучшее1) - создать минимально возможную программу, скомпилировать ее и посмотреть получившийся код. На языке NATURAL исходный код такой программы будет содержать единственный оператор - END (синтаксис языка позволяет также использовать точку - "."), символизирующий завершение текста программы. Сохраняем чудо-программу под именем test01, тип объекта2 - Program, компилируем (в терминах NATURAL "каталогизируем"), в результате чего получаем замечательный файлик test01.ngp3. Этот файл как раз и содержит "промежуточный", или GP-код.
Обратим внимание, исходный текст нашей "минимальной" программы (трехбайтный, если использовался оператор"END", и однобайтный, если использовался оператор ".") преобразовался 174-байтный. Очевидно, что структура GP-кода сложна и разнородна. Раз так, есть резон предположить, что GP-код должен иметь заголовочную область. Вот ее-то мы и попробуем определить.
1 Правильный ответ - читать документацию! Этот набивший оскомину постулат был мной проигнорирован, за что я поплатился 2 месяцами времени. Оказалось, Natural имеет полезную настройку - формирование отчета о процессе компиляции. Этот отчет - просто кладезь полезной информации! Однако в моей глупости есть и свои плюсы - был испробован в деле метод "черного ящика", что для меня оказалось весьма полезным, и надеюсь, окажется полезным и еще кому-нибудь.
2 Object type - имеется в виду тип программного модуля. Перечень возможных типов объектов и дополнительная информация по ним даны в Приложении 1, п 1.1
3 Условия кодогенерации: ОС Microsoft Windows XP [Версия 5.1.2600], Natural 6.1.1 pl9Заголовок
Логично начать поиски заголовка в начале файла. А вот где он заканчивается? Явно раньше последнего байта (где-то же должны храниться программные инструкции и едва ли внутри заголовка) и явно после последовательности "TEST01" (имя программы).
Поехали!
Пропустим пока значения 0x0 и 0xFF и сведем ценную информацию в табличку
А вот что дальше - совершенно непонятно! Мало того, что последовательность не ассоциируется ни с какой "человеческой" информацией, так она еще носит явно периодический характер! Может быть, это уже не заголовок? А что тогда?
Давайте попробуем ответить на этот вопрос, исходя из периодичности (т.е. повторяемости). Единственная оговорка, последовательность нулей (начиная с 0x30 по 0x37) рассматривать не будем из-за ее "неинформативности", а рассмотрим последовательность с 0x38 по 0x5F.
Процесс предстоит творческий - необходимо преобразовать эту последовательность в нечто осмысленное и удобоваримое. Возможно множество вариантов (не забываем отброшенную нами ранее последовательность нулей - они тоже могут быть задействованы), но я бы хотел предложить вашему вниманию лишь два
Если в первом варианте сложно найти какую-то "осмысленность", то второй вариант выглядит более любопытным: 0x60 + 0x04 + 0x08 + 0x02 + 0x40 = 0xAE, а это ни что иное, как размер GP-кода!
Вопрос - что при сложении дает общий размер? Наверное, размер элементов … А что может являться элементом скомпилированной программы? Уж не секция ли!? (можно, конечно, подобрать и другие названия этим элементам - директория, сегмент, раздел и т.д, но давайте остановимся на секции)
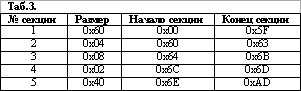
Выглядит вполне заманчиво - в начале GP-кода заголовок, за ним таблица с размерами секций. Проверим?
(0xAD таб.3 разъехалось с 0xAE таб.2 в один байт из-за того, что в таб.3 даны смещения, а в таб.2 - размеры, т.е в таб.3 мы отсчитываем от нуля, а не от единицы)
Возьмем на заметку - количество секций 5, и это количество должно бы фигурировать в заголовке (интерпретатор, переваривающий этот код, должен бы знать размер таблицы секций еще до того, как ее прочитает, чтобы корректно выделить для нее память). В заголовке (Таб.1) это число встречается всего один раз, и оно еще не опознано, а потому вполне пригодно в качестве кандидата на вакантную должность "хранителя количества секций".
Если все наши предположения верны, то в первую секцию (условно - "заголовок") вошел сам фиксированный заголовок и переменная часть - таблица секций. Вторая, третья и четвертая секции слишком малы, чтобы что-то предполагать, а структура пятой не совсем очевидна (хотя там есть любопытные закономерности, и я предлагаю вам их отыскать).
Будем экспериментировать!
Но хороший эксперимент нужно подготовить, т.е. решить, что проверяем и каким образом. Сначала убедимся, что наши предположения по структуре фиксированного заголовка верны, для чего проведем ряд экспериментов.
Хочу сразу оговориться - в жизни экспериментов было гораздо больше, и они по разным причинам были совершенно другими! Не надейтесь с одного - двух раз разобраться со сложной структурой данных. Готовьтесь к тому, что нужно будет проделать десятки, сотни экспериментов, чтобы выдвинуть только гипотезу, и десятки - чтобы ее подтвердить или опровергнуть. И обязательно все скрупулезно журнализируйте.
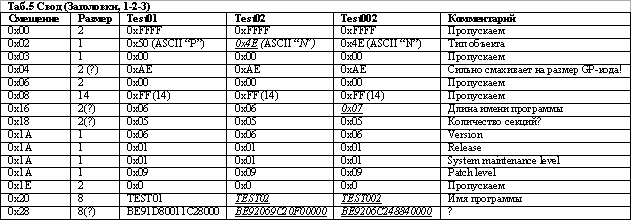
Сводим в табличку полученные после компиляции результаты:
(Курсивом c с подчеркиванием отмечены отличия от предыдущего состояния)
С расположением типа объекта и длины имени программы в структуре заголовка вроде понятно.
Отметим, что последнее поле (смещение 0x28) меняется от эксперимента к эксперименту. Мало того, если мы вообще ничего не изменим, а просто перекомпилируем исходный код, значение этого поля все равно поменяется. Как вы уже, наверное, догадались - это не что иное, как Timestamp. Т.к эта штуковина будет меняться от эксперимента к эксперименту, то давайте договоримся не обращать на нее внимания.
Таблица секций
На очереди вторая серия экспериментов - необходимо разобраться с секциями и либо получить подтверждение наших предположений, либо пересмотреть модель структуры GP-кода.
А предположили мы следующее
- По смещению 0x18 находится число, равное количеству секций
- Начиная с фиксированной позиции 0x30 и заканчивая 0x38 включительно, находится начало таблицы секций (последовательность нулей так и осталась бесхозной). Размер строки в таблице секций равен 8. Соответственно, размер всей таблицы равен [кол-во секций из заголовка] x 8
- Первый элемент строки таблицы секции - размер секции
Попутно хотелось бы получить ответ на вопрос, а где же хранятся номера строк в GP-коде? Ведь при возникновении ошибки на этапе выполнения программы помимо самого сообщения об ошибке нам сообщается и номер строки инструкции, вызвавшей ошибку! Причем отсутствие исходного кода не влияет на способность интерпретатора определять номер строки. Значит, номера строк исходного кода каким-то образом хранятся и в GP-коде!
Вот что получилось после компиляции Test04:
И что получилось после компиляции Test05:
Сводим в таблицу фиксированные заголовки
(Курсивом c с подчеркиванием отмечены отличия от предыдущего состояния)
Наше предположение о размере GP-кода подтвердилось. Также подтвердилось "интуитивно очевидное" предположение, что комментарии и пустые строки не увеличивают размер GP-кода. И, по большому счету, структура фиксированного заголовка стала довольно прозрачной. А вот с секциями (а значит, и с предполагаемой структурой GP-кода) пока до ясности далеко.
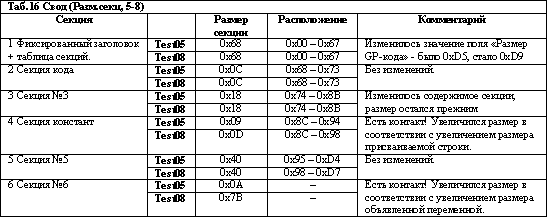
Сравнение предполагаемых таблиц секций Test01 и Test04 не выявило никаких различий, что, в общем-то, вполне ожидаемо (напомню, что исходный код Test04 отличается от Test01 строкой комментария и пустой строкой). А вот Test05 преподнесла сюрпризы! Если наши предположения насчет таблицы секций верны, то в Test05 по сравнению с Test04 (и Test01 соответственно) добавилась новая секция (что отразилось в фиксированном заголовке) и изменились размеры секций (опять-таки, если наши предположения верны).
Проверяем наше предположение, что "Первый элемент строки таблицы секции - размер секции". Если сумма первых элементов будет равна размеру GP-кода из заголовка (а она, в свою очередь - физическому размеру файла), то честь нам и хвала, если же нет - рвем на себе остатки волос, вешаем IDA на гвоздь и уходим из большого спорта!
Проверим предположение для файла Test05: 0x68 + 0x0C + 0x18 + 0x09 + 0x40 + 0x0A = 0xDF
Вот так номер! В заголовке-то 0xD5! И физический размер файла, однако, тоже 0xD5…
Предлагаю не спешить с вырыванием волос, тем же, кто успел все же выдрать клок, настоятельно рекомендую приклеить его обратно.
Очень не хочется отбрасывать гипотезу, что перед ними таблица секций и размеры секций в начале строк этой таблицы! И основным аргументом, в пользу того, что отбрасывать гипотезу рановато, является следующее. Сумма первых элементов таблицы (размеры секций, по нашему предположению) отличаются от физического размера файла ровно на последнее слагаемое!
Действительно, 0xDF - 0xD5 = 0x0A
Что это, случайность или закономерность? Придется заняться этими секциями вплотную!
Пусть первая секция остается заголовочной - ее размер с завидным постоянством в точности покрывает фиксированный заголовок и пресловутую таблицу секций. Давайте посмотрим, что представляет собой вторая секция:
Содержимое вторых секций Test01 и Test04 отличаются первым байтом (скажем больше, не только содержимое секции, но и файлов, за исключением, конечно, timestamp). Вспоминаем, Test01 и Test04 отличаются тем, что единственный оператор в первом случае находился в первой строке (с учетом того, что NATURAL нумерует строки через 10, первая строка соответствует числу 0010dec или 0x0A), а во втором - в третьей строке (т.е. 0030 dec или 0x1E). Раз это номер строки, то за ним должны операторы и операнды, т.е. сам код программы. Значит, перед нами секция, содержащая код программы?! Посмотрим, что у нас с Test5. В первом байте колонки Содержимое видим 0x14 (0020dec - вторая строка исходного кода), а в девятом байте в колонки Содержимое - 0x1E (0030 dec - третья строка исходного кода). Что ж совсем неплохо! А идентичная концовка 80 D0 FF вообще вызывает оптимизм.
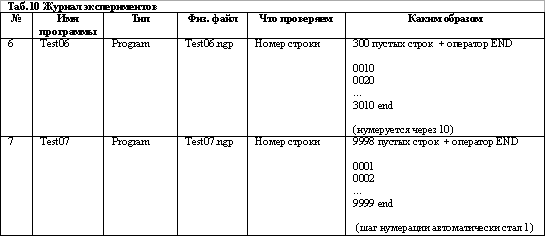
Правда, настораживает, что всего один байт зарезервирован за номером строки. Явно маловато. Из документации следует, что максимально возможное значение номера строки 9999dec , а оно в один байт никак не поместится. Чтобы внести ясность, проделаем два высокоинтеллектуальных эксперимента. В первом, исходный код будет состоять из 300 пустых строк и оператора END, а втором из 9998 пустых строк (о, боже!) и оператора END:
Вот так фокус! Два последних байта остаются неизменными, и, похоже, именно они соответствуют оператору END, а вот с двумя первыми творится что-то непонятное.
Хотя, все не так сложно. Предполагаем, что за номер строки отвечает 2 байта, меняем порядок последовательности этих байтов (что логично и правомерно), вспоминаем шестнадцатеричную систему счисления и находим весьма любопытную закономерность
Т.е, номер строки (исход. кода) = номер строки (объект. код) - 0x8000
(тонкие ценители двоичной системы счисления увидят еще более элегантное решение)
К вопросу - зачем нужны такие трудности, вернемся несколько позже, а сейчас отметим второе точное попадание с размерами секций, и вернемся к нашей таблице секций.
На очереди третья секция:
Что это такое, пока не очень понятно. Похоже, что это тоже какая-то таблица, причем она начинается и заканчивается в полном соответствии с нашими предположениями размерах секций. Выяснение назначения этой секции оставим на потом, а сейчас отметим очередное попадание - пусть и не столь убедительное, как первые два, но наша гипотеза еще вполне жизнеспособна.
Четвертая секция в наших примерах выглядит так:
Что такое 01 00 не очень понятно, а вот 77 61 73 6D 2E 72 75 не что иное, как "wasm.ru", т.е. то, что мы присвоили переменной. Уж не область ли это констант? Опять-таки, оставим выяснение этого вопроса на потом, и опять-таки, отметим жизнеспособность наших предположений относительно таблицы секций.
Содержимое пятой секции идентично для всех наших экспериментов, потому приводить ее не буду. Назначение ее не совсем очевидно, но в ней можно уверенно обнаружить следы ОС, под которой компилировалась программа.
Шестая секция…
А вот с ней как раз и сложности. Причем по простой причине - файл GP-кода закончился! Т.е. эта секция повисла в воздухе!
Давайте попробуем порассуждать (несколько раз нам это уже помогло!).
Вопрос: с чего вдруг она взялась, эта зловещая секция?
Ответ: после того, как мы объявили переменную и присвоили ей значение. И если присвоение как-то отразилось в рассмотренных ранее секциях (напомню, увеличилась секция, содержащая программный код, скорее всего именно на операцию присвоения, и увеличилась также секция с константами), то следы объявления переменной мы можем попробовать поискать только в третьей секции. Но тогда непонятно, почему объявление одной переменной добавило две строки в таблицу, содержащуюся в третьей секции? И еще более непонятно, связан ли размер секции-фантома с размером объявленной переменной (напомню, в обоих случаях он 0x0A)?
Чтобы внести ясность в возникшие вопросы, поставим еще один эксперимент, заключающийся в следующем. Модифицируем Test05 так, чтобы там объявлялась переменная с легко идентифицируемом размером.
Вот, что получим в итоге:
Мозаика собралась: если секция №6 действительно область переменных, то нет никакого смысла в ее физическом присутствии в файле GP-кода. А вот сообщить интерпретатору, что необходимо отвести определенное количество памяти под переменные - это святое.
Что ж, многое стало понятным. Мы теперь имеем некое представление о структуре GP-кода, можем с уверенностью разобрать основные поля фиксированного заголовка, определить количество, размер (а иногда и назначение!) секций. Но где начинается пресловутая таблица секций? Переиначим вопрос - где заканчивается фиксированная часть заголовка?
Смотрите, у нас есть размер всего заголовка (первая строка таблицы секций любого примера), есть количество секций в фиксированной части заголовка (т.е. количество строк в таблице секций) и есть размер строки таблицы секций. Т.е. необходимо из первого вычесть произведение второго и третьего. В результате получим (для определенности, возьмем данные Test08):
0x68 - 0x06 * 0x08 = 0x38
Т.о. фиксированная часть заголовка имеет размер 0x38 байт, а значит "неоприходованная" последовательность нулей принадлежит фиксированному заголовку.
Заключение
Попробуем схематично представить полученные сведения
GP-код программы можно условно разделить на Заголовок и Область Секций. В Заголовке в свою очередь можно выделить Фиксированную Часть Заголовка и Таблицу секций. Таблица секций содержит информацию о секциях. Структура Заголовка и Таблицы секций приведена в Приложении 1.
Следующая часть статьи будет посвящена переменным и всему, что с ними связано.
PS: Выражаю свою благодарность VOlegV за конструктивные правки и замечания.
Приложение 1
1. Структура Фиксированной части Заголовка
1.1 Перечень компилируемых типов объектов Natural
2. Структура Таблицы секций
Идентификатора секции в Таблице секций нет. Идентификация происходит по индексу, т.е. за каждой секцией "закреплен" свой индекс. Подробнее про идентификацию секций и индексы см. в следующей части статьи. © Konstantin
Исследование «промежуточного» кода на примере GP-кода языка NATURAL
Дата публикации 21 май 2006